소설 분석, googleLanguageR 소개
ropensci에서 googleLanguageR 패키지를 공개했습니다. 패키지에 관한 자세한 설명은 페이지에서 확인하실 수 있습니다. 간단히 말씀드리면, googleLanguageR 패키지는 google Cloud API의 언어 관련 API인 Google Natural Language API, Google Cloud Translation API, Google Cloud Speech API의 R interface입니다. 패키지로 할 수 있는 것을 살펴볼까요?
- 자연어 분석: 문장의 객체 인식(Named Entity Recognition), 감정 분석(Sentiment Analysis), 문법 분석(Syntax Analysis), 분류(Classification)을 지원합니다. 한국어 분류는 아직 지원하지 않습니다.
- 기계 번역: 이미 구글 번역은 유명하죠. R에서 바로바로 문장을 번역할 수 있습니다.
- 음성 인식: 녹음한 음성을 API를 통해 텍스트로 바꿔줍니다.
일단 열심히 개발하고 있던 RmecabKo가 별로 쓸모 없어질 것 같다는 위기감에 슬픔의 눈물을 뿌립니다. 이제는 그냥 구글에 소정의 사용료를 지불하고 한글 문서 올려서 분석하는 게 낫겠네요. 슬픔은 잠깐 뒤로하고, 오늘은 이 패키지를 syuzhet 패키지와 결합하여 소설의 기복을 분석하는 방법을 살펴볼 겁니다. 소설을 어떻게 분석하냐고요? 자세한 설명을 드리기 전에, googleLanguageR 패키지 설치와 활용을 먼저 살펴보고 나서, 소설 분석으로 들어가죠.
이번 포스트의 순서는 다음과 같습니다.
googleLanguageR패키지 설치와 사용- 소설 분석의 이론
- 소설 분석의 실제
googleLanguageR 설치
패키지 사용을 위해서는 먼저 Google Cloud 사용 신청을 해야 합니다.
- Google Cloud Platform에 들어가셔서 상단의 [무료 평가판 신청]을 클릭합니다. 12개월 동안 크레디트 $300을 지급하고 있고, 기본 quota도 있으니 간단한 분석에는 충분히 활용하실 수 있을 겁니다.
- Google API Consle Project 중간의 [프로젝트 만들기]의 설명을 따라갑니다. [자원 관리] - 프로젝트 생성 - 새 프로젝트 - 지불 수단 - 위치 - 생성의 단계로 입력하면 됩니다. (제가 영문으로 접속해서 한글로 뭐라고 나오는지를 모르겠네요. 죄송합니다.)
여기에서 찾으시면 되어요.
- Payment method of the project를 업데이트합니다. 아직 무료니 걱정 마셔요.
- Google Natual Language API를 활성화시킵니다. [Enable]을 클릭하면 활성화됩니다.

활성!
- Account credential을 저장합니다. [Open the list of credentials] - [Create credentials] - [Service account key] - [Service account: New service account], [JSON] - [Create] 순입니다. Account name과 Role은 임의로 정하셔도 괜찮습니다.
생성하면 .json 파일이 저장됩니다.
- 저장된 .json 파일을 원하는 디렉터리로 옮긴 뒤, R Studio를 실행시킵니다. (사용하지 않으시는 경우 텍스트 에디터)
$HOME에.Renviron파일을 만들고, 다음 내용을 입력합니다.
#.Renviron
GL_AUTH=location_of_json_file.json
R로 돌아오셔서 googleLanguageR을 설치하시면 이제 사용 가능합니다!
#install.packages("devtools")
devtools::install_github("ropensci/googleLanguageR")
googleLanguageR 실행
지금까지 잘 따라오셨으면 별다른 문제없이 API call이 가능할 겁니다. 다른 기능, Speech API와 Translate API 사용도 동일한 방식으로 진행합니다. Google Cloud API Management에서 해당 API Enable만 해주시면 돼요.
본격적으로 gl_nlp()를 알아볼까요?
gl_nlp() 함수는 텍스트를 넣으면 sentences, tokens, entities, language, text, documentSentiment의 list를 돌려줍니다. language는 언어 detection 기능인데 아직 완벽하지 않으므로 함수에 직접 parameter로 건네줄 겁니다. text는 전달한 원본 텍스트이고요, 나머지 네 개가 분석 결과입니다.
texts <- c("안녕하세요. 구글 언어 분석 데모입니다.",
"한글 분석은 아직 모든 기능을 지원하지는 않습니다.")
nlp_result <- gl_nlp(texts, language = "ko") # 언어를 한국어로 설정하는 것을 잊지 마세요.
str(nlp_result)
## List of 6
## $ sentences :List of 2
## ..$ :'data.frame': 2 obs. of 4 variables:
## .. ..$ content : chr [1:2] "안녕하세요." "구글 언어 분석 데모입니다."
## .. ..$ beginOffset: int [1:2] 0 17
## .. ..$ magnitude : num [1:2] 0.4 0.4
## .. ..$ score : num [1:2] 0.4 0.4
## ..$ :'data.frame': 1 obs. of 4 variables:
## .. ..$ content : chr "한글 분석은 아직 모든 기능을 지원하지는 않습니다."
## .. ..$ beginOffset: int 0
## .. ..$ magnitude : num 0.1
## .. ..$ score : num -0.1
## $ tokens :List of 2
## ..$ :'data.frame': 9 obs. of 17 variables:
## .. ..$ content : chr [1:9] "안녕" "하세요" "." "구글" ...
## .. ..$ beginOffset : int [1:9] 0 6 15 17 24 31 38 44 53
## .. ..$ tag : chr [1:9] "NOUN" "UNKNOWN" "PUNCT" "NOUN" ...
## ...
## ..$ :'data.frame': 12 obs. of 17 variables:
## .. ..$ content : chr [1:12] "한글" "분석" "은" "아직" ...
## .. ..$ beginOffset : int [1:12] 0 7 13 17 24 31 37 41 47 53 ...
## .. ..$ tag : chr [1:12] "NOUN" "NOUN" "PRT" "ADV" ...
## ...
## .. ..$ headTokenIndex: int [1:12] 1 10 1 7 5 7 5 10 7 7 ...
## .. ..$ label : chr [1:12] "NN" "NSUBJ" "PRT" "ADVMOD" ...
## .. ..$ value : chr [1:12] "한글" "분석" "은" "아직" ...
## $ entities :List of 2
## ..$ :Classes 'tbl_df', 'tbl' and 'data.frame': 2 obs. of 9 variables:
## .. ..$ name : chr [1:2] "구글" "언어 분석 데모"
## .. ..$ type : chr [1:2] "ORGANIZATION" "OTHER"
## .. ..$ salience : num [1:2] 0.576 0.424
## ...
## ..$ :Classes 'tbl_df', 'tbl' and 'data.frame': 3 obs. of 9 variables:
## .. ..$ name : chr [1:3] "기능" "분석" "한글"
## .. ..$ type : chr [1:3] "OTHER" "OTHER" "OTHER"
## .. ..$ salience : num [1:3] 0.324 0.269 0.407
## ...
## $ language : chr [1:2] "ko" "ko"
## $ text : chr [1:2] "안녕하세요. 구글 언어 분석 데모입니다." "한글 분석은 아직 모든 기능을 지원하지는 않습니다."
## $ documentSentiment:Classes 'tbl_df', 'tbl' and 'data.frame': 2 obs. of 2 variables:
## ..$ magnitude: num [1:2] 0.9 0.1
## ..$ score : num [1:2] 0.4 -0.1
이 중에서 제가 살펴보려고 하는 것은 documentSentiment입니다. magnitude와 score로 결괏값을 반환하네요. 각각 문장의 감정 강도와 긍정/부정 점수를 의미합니다. (entities는 객체 인식, tokens는 문장 성분 분석입니다. 객체 인식은 다른 포스트에서 다뤄보겠습니다. 문장 성분 분석은 결괏값에 관해 좀 더 세부적으로 살펴봐야 할 것 같아요.)
이 기능을 통해, 소설 분석을 시행해 볼 겁니다.
소설 분석의 이론
소설 분석이라고 하면 왠지 거창해 보이네요. 정확히는 ‘텍스트의 감정 변화 분석’이라고 불러야 정확할 것 같습니다. 우리가 흔히 기승전결이라고 부르는 구조는 소설의 내용 진행에 따른 사건의 변화 양태를 가리키지만, 그에 따른 감정의 변화 양상을 가리키기도 합니다. 보통 결말은 행복하게 끝나기 때문에, 대비를 강하게 주기 위해 절정은 부정적인 감정을 고조시키는 경우가 많습니다. 도입부와 전개에서는 소설마다 양상이 다를 테고요. 이런 생각을 시대의 달필이었던 커트 보네거트가 대중 강연에서 설명한 적이 있습니다. 영어 비디오 클립이지만, 관심 있으시면 한 번 보시면 좋을 것 같습니다.
Kurt Vonnegut on the Shapes of Stories
보네거트는 Good fortune과 Ill fortune이라는 표현을 쓰지만, 등장인물의 상황이 좋을 때 부정적 표현으로 이를 설명하기는 어렵겠죠. 반대도 마찬가지일 겁니다. 따라서 약간 proxy 이긴 하지만, 소설 전체 문장의 감정 점수를 구한 다음 이를 통해 텍스트의 진행, 소위 “narrative arc“를 그리는 것이 가능할 겁니다.
이 아이디어를 패키지로 구현한 것이 Jockers M.의 syuzhet 패키지입니다. 러시아 형식주의자들은 문학을 분석하면서 ‘파불라 fabula’와 ‘수제 syuzhet’를 구분했습니다. 파불라가 사건의 시간적 순서라면, 수제는 서사적 장치를 의미합니다.
참고로, 서사학(narratology)에서는 스토리, 담화, 플롯, 파불라, 수제를 구분합니다.
- 스토리: 서사 외적의 시간 논리(chrono-logic)에 따른 운동. 소설, 영화, 희곡이 재현되고 있는 시간에서 이야기의 진행. 카페에 앉아 누군가의 이야기를 한 시간 동안 들었다면, 스토리는 한 시간 동안 진행된 것이다.
- 담화 또는 서사담화(narrative discourse): 서사 내적의 시간 논리에 따른 운동. 카페에서 들은 이야기가 이야기하는 사람의 십 년을 요약한 서사시적 담화였다면, 서사담화는 십 년 동안 진행된 것이다.
- 파불라: 이야기 내적인 순서. “비를 맞았어. 아침에 우산을 두고 나왔거든.”에서 파불라는 [우산을 두고 나옴] -> [비를 맞음] 이다.
- 수제: 사건이 열거되는 순서. 서사를 제시하는 기법 또는 장치를 의미하기도 한다. “비를 맞았어. 아침에 우산을 두고 나왔거든.”에서 수제는 [비를 맞음] -> [우산을 두고 나옴] 이며, 화자는 비를 맞았다는 사실을 강조하기 위해 시간적 순서를 도치한 것이다.
- 플롯: 수제와 유사하나 여러 방식으로 사용됨. 일반적 대화에서는 스토리를, ‘서사적 전개’ 이론에서는 스토리를 묶는 원칙이나 역학을, ‘마스터플롯’이나 ‘복수 플롯’ 개념에서는 스토리의 유형을 의미한다.
(애벗, 서사학 강의 46~47쪽)
Jockers는 문장의 감정 분석을 통해 서사의 잠재적 구조를 분석할 수 있다고 생각합니다. 앞서 살핀 아이디어의 선을 따르고 있는 것이죠. 그는 afinn, bing, nrc 감정 사전을 통한 사전적 감정 분석(감정 단어의 숫자를 통한 감정 점수 계산)과 stanford coreNLP의 모형 기반 계산 방식을 통한 감정 분석을 통해 소설 문장의 감정을 분석한 뒤, 그 결과를 푸리에 변환하여 곡선으로 제시합니다.
패키지가 2015년 2월에 발표된 이후, 디지털 인문학 내에서도 논쟁이 좀 있었습니다. 주요 논점은 1. 감정 분석의 정확도가 떨어진다 2. 감정 분석이 정확하다고 해도, 그 결괏값(특히 푸리에 변환 이후)의 의미가 모호하다는 점이었습니다. Swafford A.는 Problems with the Syuzhet Package라는 포스트에서 syuzhet 패키지의 문제 세 가지를 지적합니다. 먼저 문장 구분(get_sentences)을 “.” 기호로 진행하기 때문에 오류가 발생한다는 것, 다음 단어에 감정값을 배정하는 방식은 한계가 있다는 것, 마지막으로 low-pass filter가 존재하지 않던 굴곡을 추가하기 때문에 오류가 발생한다는 것입니다.
첫 번째 문제는 사실 중요하지 않습니다. 개별 문장이 감정 분석의 주체가 아니라는 점, 그리고 감정 분석의 결과는 결국 평균이나 푸리에 변환을 거치기 때문입니다. 두 번째 단어 기반 분석에 관해 Jockers는 모호한 단어들로 인한 감정값의 혼동은 주변 단어들로 인해 보정된다는 답을 내놓습니다. 평균적으로 볼 때 문장 전체의 감정값은 꽤 정확하게 계산된다는 것이죠. (sentimentr 패키지의 감정 분석 기법 비교를 참조하시면 좋겠습니다.)
마지막으로 푸리에 변환에 관해 Jockers는 처음 비판을 받아들이지 않는 것처럼 보이다가, 2015년 4월 Requiem for a low pass filter라는 포스트에서 푸리에 변환을 쓰기는 어려울 것 같다는 의견을 내놓습니다. 그대로 쓰기에는 값의 왜곡이 크다는 점을 그도 인정하는 듯 보였습니다. 그러다 올해 초의 Resurrecting a low pass filter (well, kind of)에서 Jockers는 get_dct_transform 함수로 이산 코사인 변환을 추가하면서 좀 더 적절한 분석 기법을 제시하였다고 주장합니다. 아직 함수가 제작되지는 않았지만 Gao J. 등의 A multiscale thoery for the dynamical evolution sentiment in novels 논문에서는 adaptive smoother를 제시하고 있습니다. 관련 논쟁과 기법은 더 지켜봐야 할 것 같아요.
서론이 길었습니다. 요는
- 소설(또는 극본, 대본 등) 문장의 감정 분석을 통해 소설의 서사적 장치를 엿볼 수 있는 곡선을 그려볼 수 있다.
- 감정 분석은 단어 기반으로 진행되는 기법이 흔하게 사용되고 있지만 기계 학습을 통한 계산 방식도 등장하고 있다.
syuzhet패키지를 통해 이를 계산할 수 있다.
가 되겠네요.
소설 분석의 실제
그러면 직접 해봐야겠죠? 지난번 글, 시 감정 분석에서도 문제가 되었지만 현재 믿을만한 한국어 감정 사전이 존재하지 않습니다. 저도 NRC sentiment dictionary 기반으로 번역 작업을 하다 다른 일로 바빠 잠시 중단하고 있었고요. stanford coreNLP는 한국어를 지원하지 않습니다. 그러던 와중에, 구글이 API로 이를 지원하고, googleLanguageR 패키지가 발표되어 한번 분석을 해볼만하겠다는 생각에 이르게 되었습니다.
이번 분석에 사용할 소설은 이인직의 혈의 누입니다. 한국문학 최초의 신소설이자, 청일전쟁을 배경으로 한 개화기의 시대상을 그리고 있는 작품이죠. 하지만 이완용의 비서였던 그의 소설은 일본을 모형으로 하여 조선이 개화해야 한다는 주장을 그대로 드러내고 있다는 점에서, 그 이후의 역사를 알고 있는 사람이 고운 시선으로 바라보기는 어려운 작품이기도 합니다. 이 작품을 택한 이유는 일단 저작권이 없는 소설 중 길이가 어느 정도 이상이라는 점, 인터넷 본이 한글 전용 표기를 해 놓았다는 점이 컸습니다만, 분석 결과로 쓴소리를 할 수 있을까 하는 점도 선정 요소로 작용했습니다.
소설 줄거리는 다음과 같습니다. 주인공 옥련은 평양에서 부모를 잃고 헤매다가 일본인 군의관 이노우에에게 도움을 받고 일본으로 가서 학교를 다니게 됩니다. 이후 개인적 시련을 거치지만 구완서를 만나 함께 미국으로 유학을 떠나게 되죠. 죽은 줄 알았던 아버지를 다시 만난 옥련은 구완서와 약혼하고, 어머니는 옥련의 편지를 받게 됩니다.
먼저, 코드를 볼까요. 소설 원문은 직지위키에서 구했습니다.
library(tidyverse)
library(rvest)
library(magrittr)
library(stringr)
library(googleLanguageR)
library(syuzhet)
library(ggplot2)
중간에 scraping 한 원문을 줄 번호로 선택하기 위해 magrittr 패키지를 추가했습니다. 나머지는 그동안 써왔던 패키지인 것 같고, googleLanguageR과 syuzhet 패키지가 오늘 분석의 주인공입니다.
tearsofbloodUrl <- "http://www.jikji.org/혈의%20누?highlight=%28%5CbCategory소설%5Cb%29"
tobText <- read_html(tearsofbloodUrl) %>%
html_nodes(xpath="//div[@id='content']/*") %>%
extract2(25:401) %>% # magrittr::extract2 or `[[`
as.character() %>%
str_replace_all("<sup>.*</sup>", "") %>% # 각주 제거
str_replace_all("<.*?>", "") %>% # html tag 제거
as_tibble()
본문 중간에 각주 처리가 되어 있어서, html_nodes로 완전히 작업을 끝내지 못하고 텍스트로 바꾼 뒤 regular expression으로 태그를 정리했습니다. 결괏값으로 벡터 하나에 문단 하나씩 들어가게 되는데, 굳이 문장으로 더 쪼개지는 않았습니다. 이유는 1. 개별 문장의 감정값을 정확히 구하는 게 중요하지 않고, 2. google API를 사용하기 때문에 query 수를 최대한으로 줄이기 위함입니다.
tobSentiment <- lapply(tobText, function(x) gl_nlp(x)$documentSentiment, language="ko")
tobText <- tobText %>%
mutate(id = row_number()) %>%
add_column(tobText, magnitude = tobSentiment$value$magnitude, score = tobSentiment$value$score)
str(tobText)
## Classes 'tbl_df', 'tbl' and 'data.frame': 377 obs. of 4 variables:
## $ value : chr "청일전쟁의 총소리는 평양 일경이 떠나가는 듯하더니, 그 총소리가 그치매 사람의 자취는 끊어지고 산과 들에 비린 티끌뿐이라. \n" "평양성의 모란봉에 떨어지는 저녁 볕은 뉘엿뉘엿 넘어가는데, 저 햇빛을 붙들어매고 싶은 마음에 붙들어매지는 못하고 "| __truncated__ "남이 그 모양을 볼 지경이면 저렇게 어여쁜 젊은 여편네가 술 먹고 한길에 나와서 주정한다 할 터이나, 그 부인은 술 "| __truncated__ "무슨 소회가 그리 대단한지 그 부인더러 물을 지경이면 대답할 여가도 없이 옥련이를 부르면서 돌아다니더라. \n" ...
## $ magnitude: num 0.4 0.8 0.9 0.5 2.5 0.7 0.5 1.3 0.2 0.7 ...
## $ score : num 0.4 -0.8 -0.9 -0.5 0 0.7 -0.5 -0.1 -0.2 0.3 ...
## $ id : int 1 2 3 4 5 6 7 8 9 10 ...
tobText
## # A tibble: 377 x 4
## value
## <chr>
## 1 "청일전쟁의 총소리는 평양 일경이 떠나가는 듯하더니, 그 총소리가 그치매 사람의 자취는 끊어지고 산과 들에 비린 티끌뿐이라. \n"
## 2 "평양성의 모란봉에 떨어지는 저녁 볕은 뉘엿뉘엿 넘어가는데, 저 햇빛을 붙들어매고 싶은 마음에 붙들어매지는 못하고 숨이 턱에 닿은 듯이 갈팡질팡하는 한 부인이 나이 삼십이 될락말락하고, 얼굴은 분을 따고 넣은 듯이 흰 얼굴이나 인정 없이 뜨겁게 내리쪼이는 가을볕에 얼굴
## 3 "남이 그 모양을 볼 지경이면 저렇게 어여쁜 젊은 여편네가 술 먹고 한길에 나와서 주정한다 할 터이나, 그 부인은 술 먹었다 하는 말은 고사하고 미쳤다, 지랄한다 하더라도 그따위 소리는 귀에 들리지 아니할 만하더라. \n"
## 4 "무슨 소회가 그리 대단한지 그 부인더러 물을 지경이면 대답할 여가도 없이 옥련이를 부르면서 돌아다니더라. \n"
## 5 "“옥련아, 옥련아 옥련아 옥련아, 죽었느냐 살았느냐. 죽었거든 죽은 얼굴이라도 한번 다시 만나 보자. 옥련아 옥련아, 살았거든 어미 애를 그만 쓰이고 어서 바삐 내 눈에 보이게 하여라. 옥련아, 총에 맞아 죽었느냐, 창에 찔려 죽었느냐, 사람에게 밟혀 죽었느냐.
## 6 "하면서 옥련이를 찾으려고 골몰한 정신에, 옥련이보다 열 갑절 스무 갑절 더 소중하게 생각하는 사람을 잃고도 모르고 옥련이만 부르며 다니다가 목이 쉬고 기운이 탈진하여 산비탈 잔디풀 위에 털썩 주저앉았다가 혼자말로 옥련 아버지는 옥련이 찾으려고 저 건너 산 밑으로 가더
## 7 "기다리는 사람은 아니 오고, 인간 사정은 조금도 모르는 석양은 제 빛 다 가지고 저 갈 데로 가니 산빛은 점점 먹장을 갈아붓는 듯이 검어지고 대동강 물소리는 그윽한데, 전쟁에 죽은 더운 송장 새 귀신들이 어두운 빛을 타서 낱낱이 일어나는 듯 내 앞에 모여드는 듯하니,
## 8 "“에그, 깜깜하여라. 이리 가도 길이 없고 저리 가도 길이 없으니 어디로 가면 길을 찾을까. 나는 사나이라 다리 힘도 좋고 겁도 없는 사람이언마는 이러한 산비탈에서 이 밤을 새고 사람을 찾아다니려 하면 이 고생이 이렇게 대단하거든, 겁도 많고 다녀 보지 못하던 여
## 9 "하는 소리를 듣고 부인의 마음에 난리중에 피란 가다가 부부가 서로 잃고 서로 종적을 모르니 살아 생이별을 한 듯하더니 하늘이 도와서 다시 만나 본다 하여 반가운 마음에 소리를 질렀더라. \n"
## 10 "“여보, 나 여기 있소. 날 찾아 다니느라고 얼마나 애를 쓰셨소.” \n\n"
## # ... with 367 more rows, and 3 more variables: magnitude <dbl>, score <dbl>,
## # id <int>
다음, gl_nlp 함수를 적용해 감정값을 구했습니다. 결괏값을 텍스트에 붙이고 줄번호를 매겨 분석 대상 자료틀을 완성합니다.
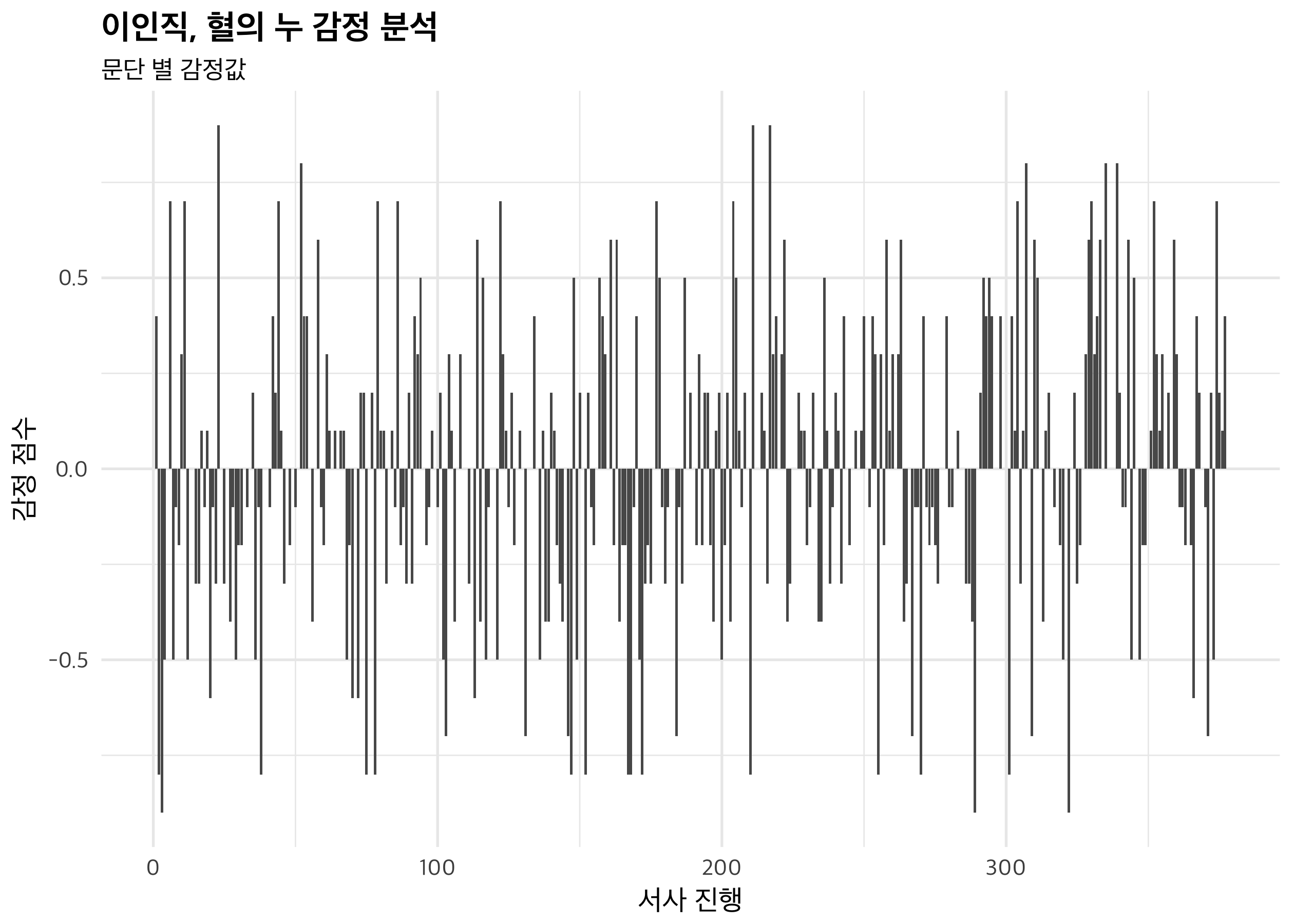
문단마다 값이 크게 차이를 보이기 때문에, 경향성을 파악하기가 어렵습니다. syuzhet 패키지를 통해 결괏값을 smoothing 해 볼까요.
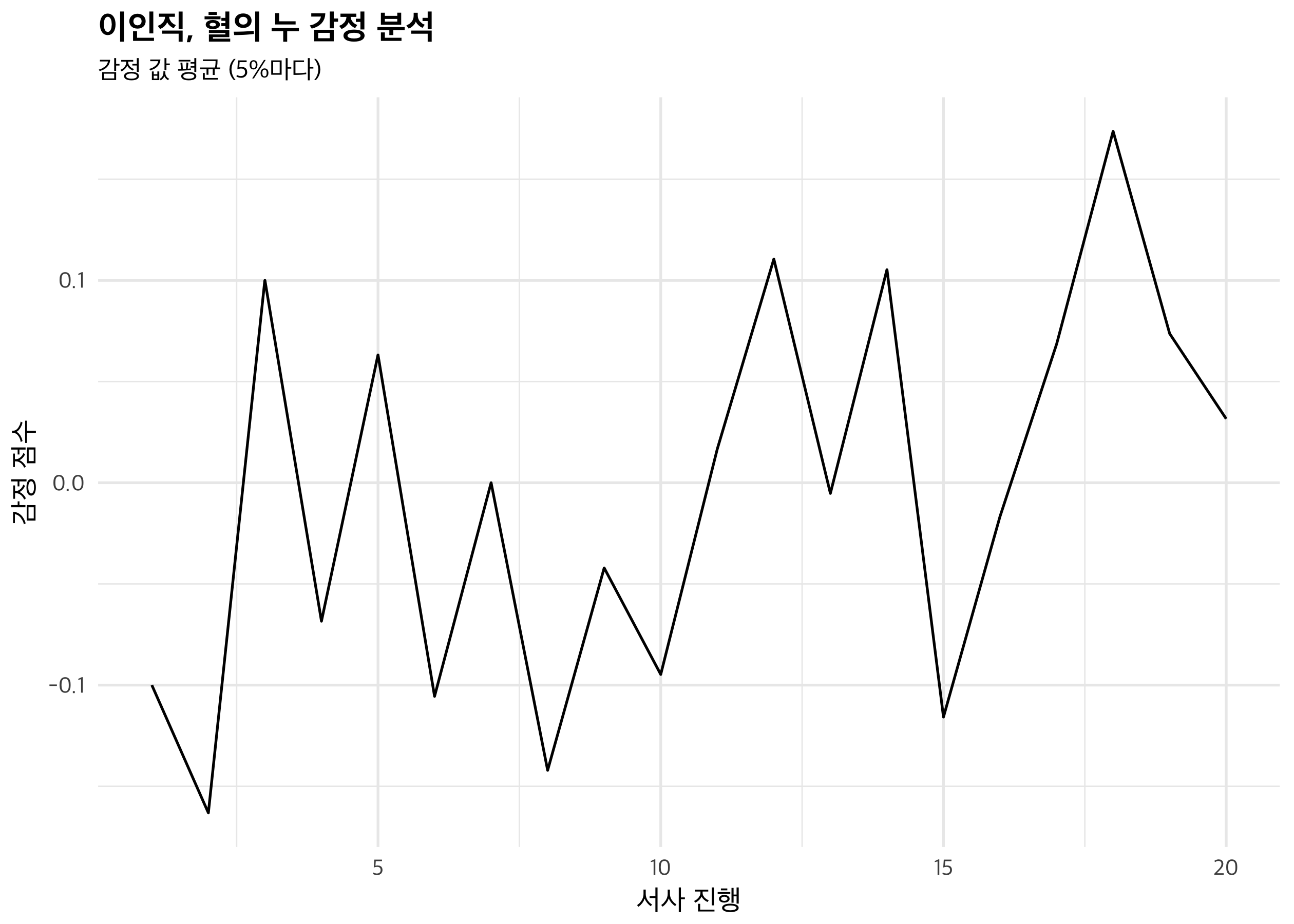
대충 얼개는 볼 수 있을 것 같습니다. 초반의 불행(1-2)에서 이노우에의 도움과 일본 이주(3-5), 이노우에의 죽음과 옥련의 고난(6-10), 미국 유학(11-14), 옥련 어머니의 고난(15), 옥련의 편지와 가족의 재회(16-20)라고 보면 대충 맞을 것 같네요. 하지만 곡선이 예쁘지는 않으니, 앞서 언급한 푸리에 변환과 이산 코사인 변환을 적용해 봅시다.
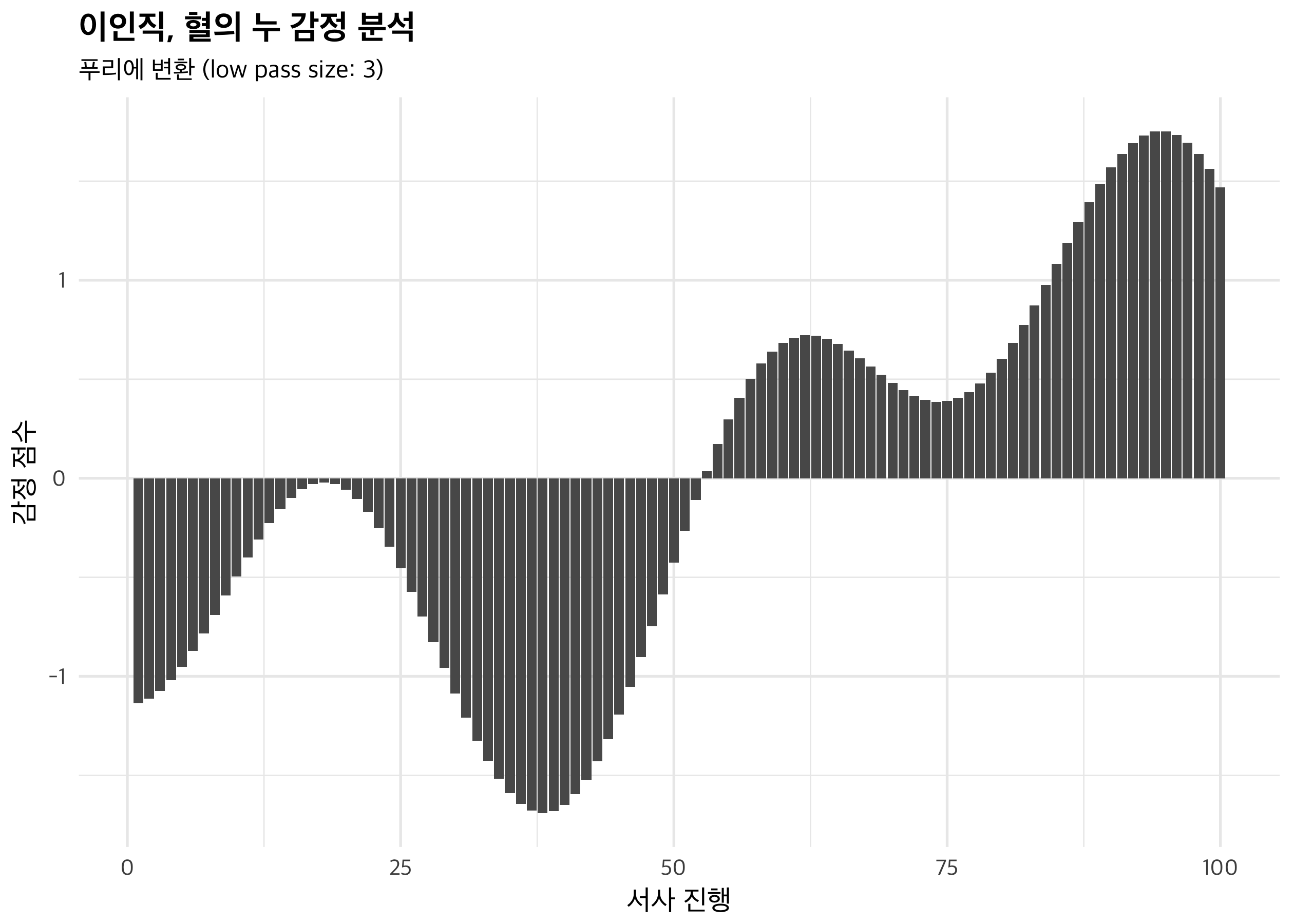
좀 더 매끈한 곡선이 되었네요. 중반을 기점으로 서사의 분위기가 반전된다는 점, 오히려 극의 갈등이 극에 달하는 점이 전개 부분이라는 점에서 소설의 전개가 그렇게 매끄럽지는 않다고 볼 수도 있겠습니다. 물론, 이 그래프를 가지고 소설을 비판하는 것에는 한계가 있습니다. 그래도 도식적인 소설이라는 생각을 지지해주는 자료로는 사용 가능할 것 같아요. 조선의 비극적 상황과 외국에서의 창창한 앞날을 대비시키는 것이라는 점 말입니다.

푸리에 변환과 비슷하지만 좀 더 그럴듯한 결과물이 나왔습니다. 그렇다고 해도 해석 자체에 큰 차이가 있지는 않을 것 같네요. 조선과 외국의 극명한 대비, 더 정확히는 미국 생활에 대한 동경을 엿볼 수 있다고 해야 할지요. 그나마 소설 초반에서 긍정적으로 그려지는 것은 일본인 군의관 이노우에라는 점 또한, 일본의 조력을 통한 조선의 개화 또는 개선이라는 소설의 문제 인식을 잘 보여주고 있다는 생각도 들고요.
마지막으로, 세 변환을 겹쳐서 확인해볼까요? 중복인 것 같아 시각화 코드는 여기만 올립니다.
data_frame(x = 1:100,
FFT = get_transformed_values(tobText$score, low_pass_size = 3, x_reverse_len = 100, scale_vals = TRUE)[, 1],
DCT = get_dct_transform(tobText$score, low_pass_size = 6, x_reverse_len = 100, scale_vals = TRUE)[, 1],
PER = get_percentage_values(tobText$score, bins = 100)) %>%
gather(smoothing, value, -x) %>%
ggplot(aes(x = x, y = value, colour=smoothing)) +
geom_line() +
labs(title = "이인직, 혈의 누 감정 분석",
subtitle = "변환 방법 별 비교",
x = "서사 진행",
y = "감정 점수")
![]()
이 소설 하나로 어느 변환 방법이 더 좋다고 말하기는 어려울 것 같습니다. 구간 평균(비교를 위해 일단 100단계로 줄였습니다)은 원래 값과 가독성이 비슷한 것 같고, 푸리에 변환과 이산 코사인 변환은 이 소설에서는 큰 차이가 나지 않네요. 다른 소설 분석을 더 해봐야 할 것 같습니다.
마치며
한글 문서 감정 분석에서 개인적으로 돌파구를 찾지 못하고 있던 상황에서, 이번 googleLanguageR의 발견은 하나의 전기를 주는 건 확실합니다. 반면, 분석 툴의 개발이 과연 무슨 소용이 있는가라는 생각도 드네요. 한글 감정 분석 사전 프로젝트는 잠정적으로 중단해야겠다는 생각도 들고요.
아무쪼록, 다른 분석에도 많이 활용해보셨으면 하는 마음입니다. 영화나 드라마 대본도 동일한 방법론으로 분석 가능하니, 저도 다음번에는 영화 분석 결과를 한 번 올려볼게요. 긴 명절, 행복하게 누리시길!
Comments