시진은 뛰고, 모연은 건넨다 - "태양의 후예" 대본 텍스트 분석
아래 분석은 Silge J. She giggles, he gallops가 제시한 텍스트 분석 기법을 한글 텍스트에 적용해본 예제입니다. 원문은 Anderson H, Daniels M. Film dialogue의 작업에서 만든 2000개의 영화 대본을 바탕으로 연어(bigram)를 검토, 대명사인 “he”와 “she”에 붙어 있는 단어를 찾아 나갑니다. 영어 구조 상, 대명사 뒤에는 동사가 따라나올 것이며, 따라서 영화 대본이 남자와 여자에게 어떤 행동을 지시하는 지를 파악할 수 있게 되겠지요. 결과, “he”는 “straps(채찍질하다)”, “gallops(말 달리다)”, “shot(쏘다)” 등의 행동을, “she”는 “snuggles(껴안다)”, “giggles(낄낄거리다)”, “squeals(울고 비명지르다)” 등의 행동을 더 많이 수행합니다. 영화에서 남, 여 등장인물에 관한 고정관념을 수치로 확인할 수 있는 훌륭한 분석이라고 생각합니다. 시대, 작가 등에 따른 차이도 제시해 놓았으니 링크는 한번 꼭 보셔요.
이런 작업을 보면 한글로 한번 해봐야 하지 않겠습니까. 영화 대본 수집은 다른 기회에 한번 도전해보도록 하고, 이번에는 검색하다가 인기 드라마였던 “태양의 후예” 1~16화 대본을 발견해서, 이 자료를 통해 분석해보기로 했습니다. 다음에는 김은숙 작가의 작품들을 모아서 해볼까 싶기도 해요. 오늘은 일단, 어떤 식으로 분석을 진행하는지만 간단히 확인해 보겠습니다.
사전 처리
이번에 사용한 라이브러라는 특별한 건 없습니다. 시각화를 위해 ggbeeswarm을 사용한 것 정도일까요. 대본은 pdf 형태여서, html로 변환하여 불러왔습니다. 표 형태처럼 되어 있는 부분이 많고 다단 편집이 된 경우도 있어서, pdftools 등으로 바로 불러오면 문단 구조가 어긋나게 됩니다. rvest로 불러와서 필요한 문장을 선택합니다.
- 대사의 경우 “등장인물 대사”의 형태로 기록되어 있어서, 정규식으로 삭제했습니다.
- 줄바꿈이 들쭉날쭉해서 합친 뒤 마침표, 느낌표 기준으로 다시 분리하고,
- 남은 대사와 기호를 제거합니다.
완성한 결과를 data frame 형태로 뽑았는데, 이번 작업에서는 그냥 character vector만 추출했어도 됐을 것 같아요. 합쳐서 용언, 체언만 추출하고 두 주인공의 이름이 들어간 문장들을 모아, 새로운 data frame을 만듭니다. 한국어는 “he”, “she”의 구분이 없기 때문에, 주인공 이름이 적당하리라고 생각했어요.
library(tidyverse)
library(tidytext)
library(rvest)
library(stringr)
library(KoNLP)
library(ggbeeswarm)
user_d <- data.frame(term=c("민지"), tag=rep("nq", 1))
buildDictionary(ext_dic=c("woorimalsam", "insighter"), user_dic=user_d, replace_usr_dic=FALSE)
files <- list.files(pattern="html$")
get_txt_html <- function(html_file) {
page <- read_html(html_file)
doc <- page %>%
html_nodes(xpath="//p[@class='MsoBodyText']") %>%
html_text()
doc <- doc[str_detect(doc, "^[가-힣]{2,4} ")]
doc <- paste(doc, collapse=" ")
doc <- unlist(strsplit(gsub("([가-힣][\\.|!])", "\\1~", doc), "~"))
doc <- doc[!str_detect(doc, "[가-힣1E]{2,5}[\\s]{2}")]
doc <- doc %>%
str_replace_all("[:punct:]", "") %>%
str_replace_all("[\\r\\n]", "") %>%
str_trim(side="both")
df <- data_frame(text=doc, title=str_extract(html_file, "[0-9]+")) %>%
mutate(line=row_number())
df
}
docs <- bind_rows(lapply(files, get_txt_html))
ko_words <- function(doc) {
d <- as.character(doc)
pos <- unlist(SimplePos09(d))
extracted <- str_match(pos, '([가-힣]+)/[NP]')
keyword <- extracted[, 1]
keyword[!is.na(keyword)]
}
texts <- Map(ko_words, docs$text)
df <- bind_rows(data_frame(word=unlist(texts[str_detect(texts, "시진/N")]), character="he"),
data_frame(word=unlist(texts[str_detect(texts, "모연/N")]), character="she"))
시각화 1. Difference of log ratio
이제 시각화입니다. 먼저 용언을 추출하고, 여기에 “다”를 붙여서 동사형으로 바꿔주었습니다. 다음, 전체 단어에서의 비율과 상대 로그비를 구해서 로그비 기준으로 정렬합니다. 시각화는 로그비 절대값 기준으로 높은 단어들을 모아 보았어요.
ratio <- df %>%
filter(str_detect(word, "/P")) %>%
mutate(word2=str_replace_all(.$word, "/P", "다")) %>%
select(-word) %>%
count(character, word2) %>%
spread(character, n, fill=0) %>%
mutate(total=he+she,
he=(he+1)/sum(he+1),
she=(she+1)/sum(she+1),
logratio=log2(she/he)) %>%
arrange(desc(logratio))
ratio %>%
top_n(200, total) %>%
group_by(logratio < 0) %>%
top_n(15, abs(logratio)) %>%
ungroup() %>%
mutate(word = reorder(word2, logratio)) %>%
ggplot(aes(word, logratio, color = logratio < 0)) +
geom_segment(aes(x = word, xend = word,
y = 0, yend = logratio),
size = 1.1, alpha = 0.6) +
geom_point(size = 3.5) +
coord_flip() +
labs(x = NULL,
y = "Relative appearance after 'she' compared to 'he'",
title = "<태양의 후예>, 시진과 모연의 행동",
subtitle = "대본 지시문을 바탕으로") +
scale_color_discrete(name = "", labels = c("More 'she'", "More 'he'")) +
scale_y_continuous(breaks = seq(-3, 3),
labels = c("0.125x", "0.25x", "0.5x",
"Same", "2x", "4x", "8x"))
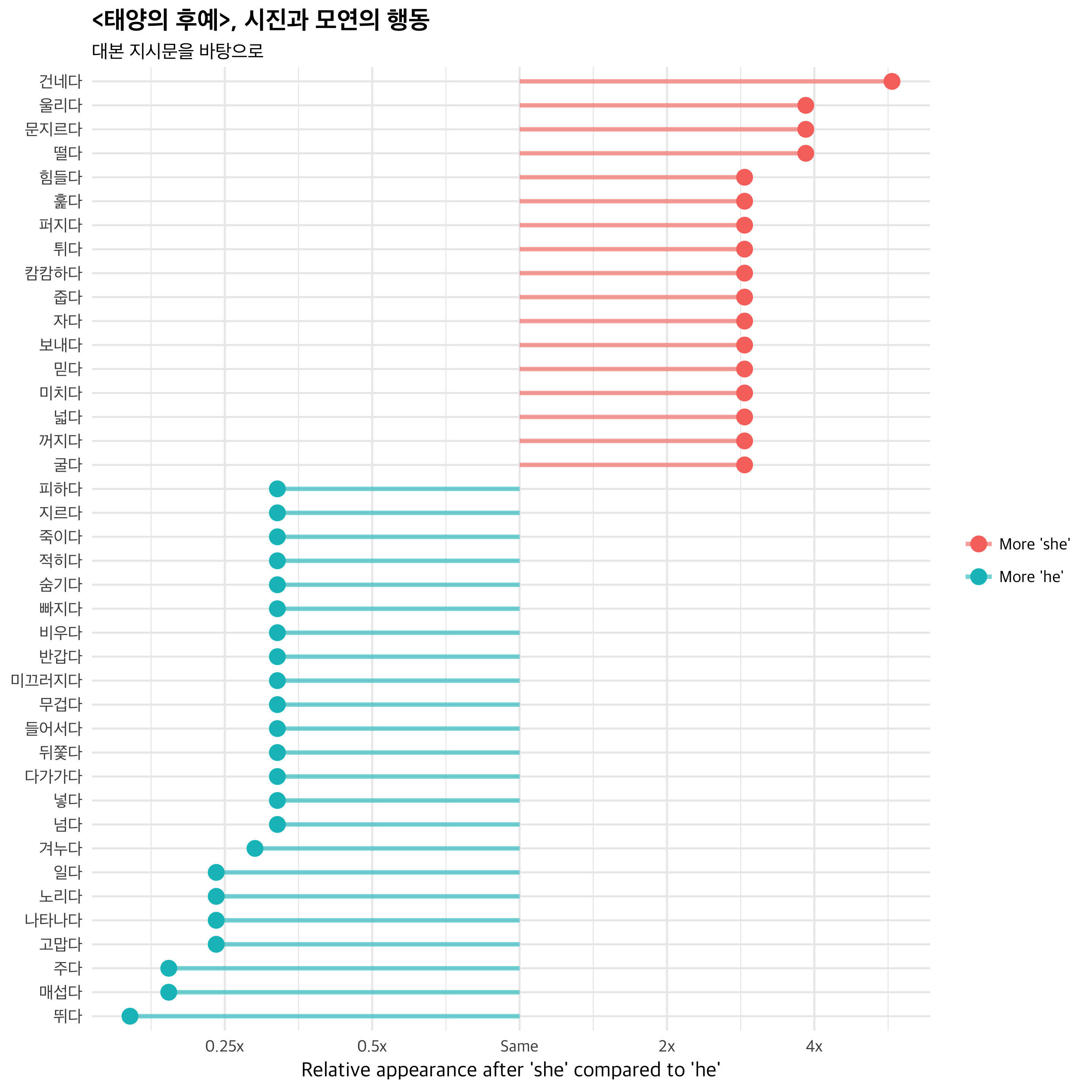
시진은 뛰고, 매섭고, 주고, 고마워하고, 나타납니다. 한편 모연은 건네고, 울리고(소리가 울리다의 울리다 입니다), 문지르고, 떨고, 힘들어하네요. 단일 작품에서의 분석이기 때문에 이것을 남여의 고정관념에 관한 결과라고 볼 수는 없을 것입니다. 하지만, 남녀 주인공의 행동에 어떤 차이가 있는지는 잘 나타나네요.
시각화 2. Beeswarm Plot
다음은 beeswarm plot입니다. beeswarm plot은 산포도인데, 위아래로 늘어놓고 같은 값의 경우는 옆으로 퍼뜨린 그림이예요. 먼저 위 그림을 beeswarm plot으로 그려본 결과입니다.
ratio %>%
top_n(400, total) %>%
mutate(blank = "blank",
word = reorder(word2, logratio)) %>%
ggplot(aes(blank, logratio, label = word2)) +
geom_beeswarm(color = "midnightblue", alpha = 0.4) +
geom_text(family = "Apple SD Gothic Neo", size = 2.5,
vjust = 1.2, hjust = 1.2,
check_overlap = TRUE) +
theme_void()
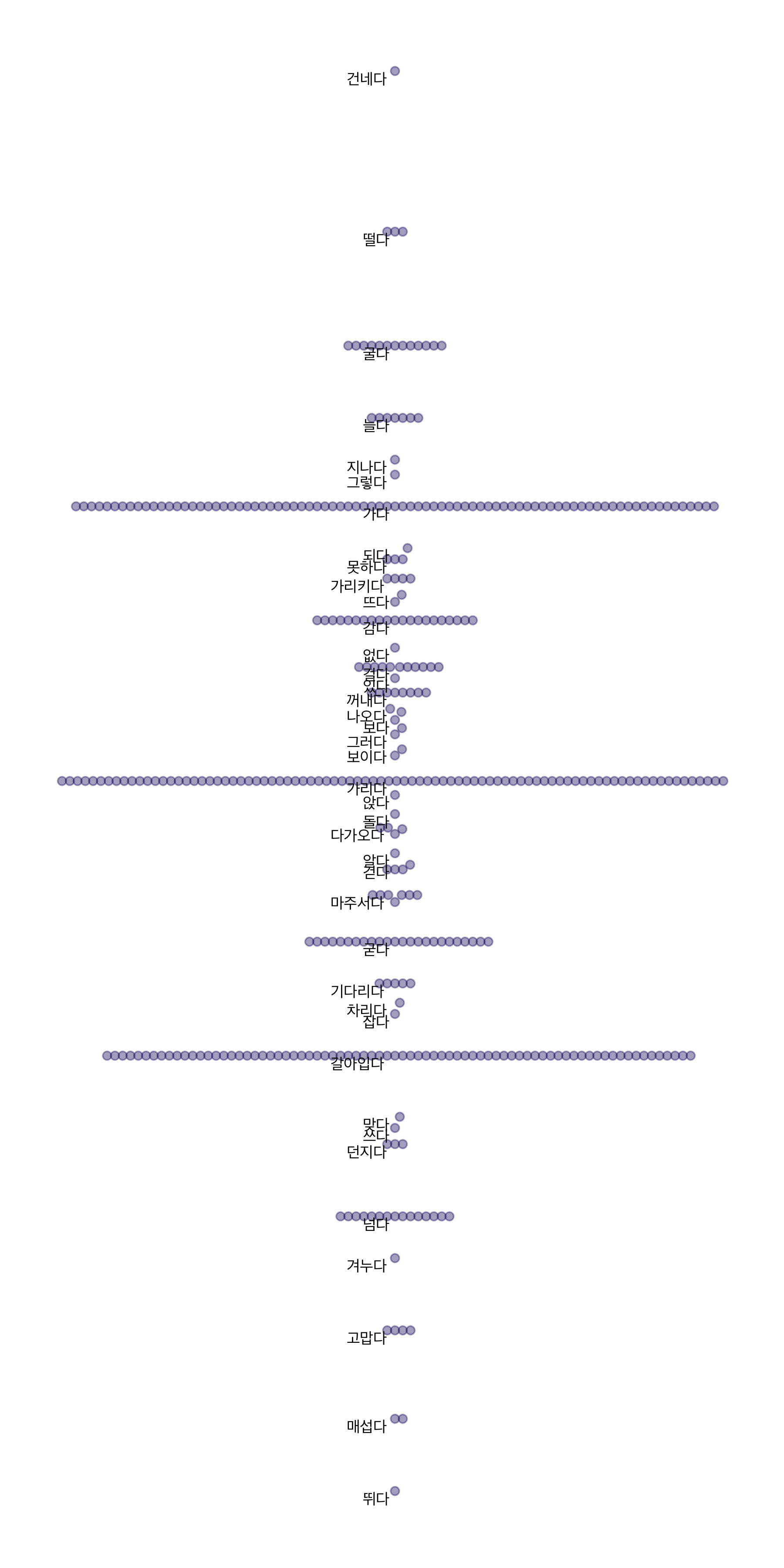
위쪽으로 갈수록 여주, 아래쪽으로 갈수록 남주의 행동을 지시하는 단어입니다. 가운데의 단어들은 비슷한 비율로 나타나고 있는 단어들이겠죠. 그럼, 비율에 따라서 남, 여 별도로 시각화해볼게요.
ratio %>%
top_n(200, total) %>%
select(-total) %>%
gather(she, he, -word2, -logratio) %>%
rename(gender=she, ratio=he) %>%
mutate(word = reorder(word2, logratio)) %>%
ggplot(aes(gender, ratio, label = word2)) +
geom_beeswarm(color = "midnightblue", alpha = 0.4) +
geom_text(family = "Apple SD Gothic Neo", size = 2.5,
vjust = 1.2, hjust = 1.2,
check_overlap = TRUE)
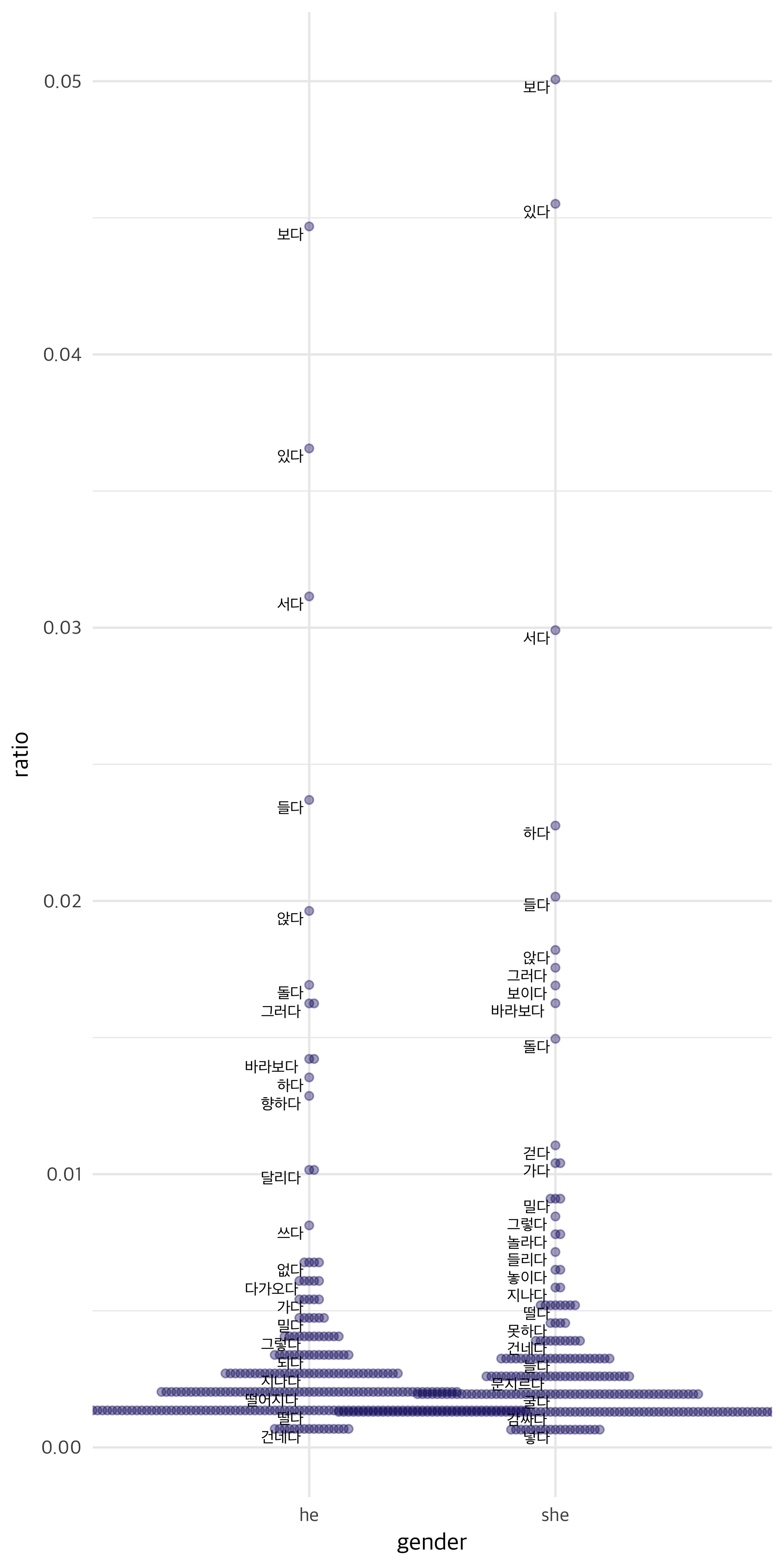
오히려 별다른 차이를 잘 모르겠어요. 단어 분포가 다르다는 건 알겠지만 라벨을 다 붙일 수가 없으니, 시각화 결과로는 조금 애매하지 싶네요.
예시 문장 검색
마지막으로, 해당 단어가 출현한 문장 예시를 추출해 보았습니다. 먼저 중요 단어를 모아서 data frame으로 만들고, 처음 구축한 자료에서 여주(모연)와 여주의 행동을 지시하는 단어가 들어간 문장의 sample을, 다음 남주(시진)와 남주의 행동을 지시하는 단어가 들어간 문장의 sample을 추출해 data frame을 구축합니다.
example_words <- ratio %>%
top_n(400, total) %>%
head(20) %>%
mutate(word=str_replace_all(.$word2, "다$", "/P")) %>%
select(word) %>%
bind_rows(ratio %>%
top_n(400, total) %>%
tail(20) %>%
mutate(word=str_replace_all(.$word2, "다$", "/P")) %>%
select(word)) %>%
pull(word)
docs$pos <- texts
example_text <- bind_rows(data_frame(base = example_words[1:20]) %>%
mutate(text = map_chr(base, function(x) docs %>%
filter(nchar(text) < 180,
str_detect(pos, "모연/N")) %>%
filter(str_detect(pos, x)) %>%
sample_n(1) %>%
pull(text))) %>%
mutate(word=str_replace_all(base, "/P", "다")) %>%
select(word, text),
data_frame(base = example_words[21:40]) %>%
mutate(text = map_chr(base, function(x) docs %>%
filter(nchar(text) < 180,
str_detect(pos, "시진/N")) %>%
filter(str_detect(pos, x)) %>%
sample_n(1) %>%
pull(text))) %>%
mutate(word=str_replace_all(base, "/P", "다")) %>%
select(word, text))
example_text
## # A tibble: 40 x 2
## word text
## <chr> <chr>
## 1 건네다 고반장 다가와 모연에게 차 키 건네며 씁쓸한 표정으로 복도 걷는 시진
## 2 떨다 식당 나가는 아구스 일행 따라 점점이 멀어지는 시진과 대영 보던 모연 떨고 있는 파티마 등 가 만가만 쓸어주고
## 3 문지르다 고개 푹 숙인 채 괜히 손에 묻은 피 문질러 지우고 서 있는 모연이다
## 4 울리다 복도 걸어가던 모연 쩌렁쩌렁 울리는 자신의 목소리에 굳어 서는데
## 5 굴다 그 위로 시작되는 모연의 군가
## 6 꺼지다 나머지 텐트들 다 불 꺼져 있고 모연의 텐트에만 불빛 흐릿한데 그 순간 탁 꺼지는 불빛
## 7 넓다 그런 모연의 표정에서 화면 넓어지면 조금 떨어진 곳에서 역시 추도식 풍경을 바라보고 서 있는 남자 아구스다
## 8 미치다 미친 듯이 달려 나가는 모연이고
## 9 믿다 믿을 수 없어서 받을 생각도 못하고 그저 덜덜 떨며 바라만 보고 선 모연인데
## 10 보내다 당신 그렇게 보내고 내 맘이 얼마나 불편했는지 짐작이 가나 혹시 화난 얼굴로 모연 보다가 멋지게 확 돌아서 저벅저벅 가버리는
## # ... with 30 more rows
텍스트 분석에서는 어떤 문장들이 선택되었는지 제시해 줄 필요가 있는 것 같습니다. 단어만으로는 의미 파악이 어려우니까요. 지난번 보았던 LDA 등에서도, topic 구축을 단어 만으로 하지는 않고 결국 일치도가 가장 높은 텍스트를 보면서 topic 명을 정하곤 합니다.
마치며
어떠셨는지요? 간단하게 진행해본 예제라, 좀 밋밋합니다. 남주와 여주의 차이를 엿볼 수 있어서, 개인적으로는 흥미로웠습니다(“태양의 후예”에서 제시된 의사상에 관한 독해를 준비하고 있거든요). 다음 분석 자료에서는 더 많은 대본을 모아서 분석해볼 수 있으면 좋겠어요. 지금 deep learning 관련 포스트 준비 때문에 언제가 될진 모르겠네요. 다음 분석과 함께 다시 찾아뵙겠습니다.
Comments