환자 불편 상담에 관한 Latent Dirichlet Allocation 분석
이번에는 지난 번에 활용했던 1372 소비자보호원 상담 자료를 통해 LDA (Latent Dirichlet Allocation)을 통한 분석을 진행해 보려 합니다. 먼저 참고한 페이지는 다음과 같습니다.
- http://tidytextmining.com/topicmodeling.html
- http://davidmeza1.github.io/2015/07/20/topic-modeling-in-R.html
- https://begriffs.com/posts/2015-02-25-text-mining-in-r.html
- https://ldavis.cpsievert.me/reviews/reviews.html
LDA?
Latent Dirichlet Allocation은 텍스트 분류를 위해 등장한 여러 방법론 중 하나입니다. 일전에도 간략하게 말씀드린 적이 있지만, Document-Term Matrix(각 문서 별로 출현한 단어의 빈도를 나타낸 행렬)로 텍스트를 표현하여 각 단어의 등장 빈도에 따라 텍스트를 분류하려는 시도가 계속 이루어졌습니다. 그것은 분야에 따라 사용되는 단어가 다르다는 관찰에 기반하는데요, 예컨대 ‘드리블’이라는 단어가 나오는 텍스트면 축구 또는 스포츠 관련 텍스트겠지요. ‘염좌’나 ‘폐렴’이 나오는 텍스트는 아마 의학 관련 텍스트일 겁니다. 하지만 이 단어들은 문학에서도 나타날 수 있겠지요.
그렇다면 특정 단어의 출현 여부를 넘어, 단어의 빈도가 텍스트의 분류를 결정할 수도 있을 것 같습니다. 예컨대 ‘폐렴’은 의학 교과서와 철학자 손택의 에세이 ‘질병이라는 은유’ 모두에 나오지만, 의학 교과서에서 더 많이 사용되었을 것이며, ‘폐렴’과 ‘폐수종’이 나타나는 경우 의학 교과서일 가능성이 더 높을 것입니다. 반면 ‘폐수종’은 손택의 에세이에서는 나타나지 않습니다. 즉, 여러 단어의 출현 빈도를 바탕으로 텍스트의 원 분류를 추측해보는 것이 텍스트 분류의 비지도 학습(Unsupervised learning of text classification)입니다.
처음에 제시된 것은 LSA(Latent Semantic Analysis)였습니다. Document-Term Matrix의 역행렬인 Term-Document Matrix의 low-rank approximation을 구하는 방식으로 접근하고, 이를 위해 SVD(Singular Value Decomposition)를 통한 차원 축소를 시행합니다. 두개 차원으로 축소하면, 텍스트를 이차원 평면에 도시하여 그 분포를 확인해볼 수도 있겠네요.
계산이 간편하고 꽤 정확하게 들어맞는 경우들이 있어서 LSA도 여전히 사용되고 있지만, 이후 방법론은 발전을 거듭합니다. 그리고, 오늘 살펴볼 LDA는 최근 활발하게 연구되고 있는 방법론으로서, 단어의 사전 분포와 텍스트의 사전 분포가 있음을 가정하는 베이지안 기법을 통해, 단어와 텍스트의 분포를 추정하여 해당 텍스트의 주요 단어와 분류를 추측하는 방식입니다. 장점으로는 1. 분류에서 가장 중요도가 높은 단어들을 추출하여 해당 분류의 주제(topic)가 무엇인지 추측해볼 수 있다 2. 다항 분포의 사전 켤레확률인 Dirichlet 분포를 사용하여 모수를 가정하지 않으며, 계산이 간편하다 등을 제시할 수 있을 것 같습니다.
이번에는, 치과 자료만 모아서 LDA를 통해 중요 단어를 추출, 상담 사례를 어떻게 분류할 수 있는지 확인해볼 것입니다.
사용 package
새로운 패키지가 몇 개 추가되었어요. lubridate는 손쉽게 character 형식을 date 형식으로 바꿔주는 패키지입니다. tm은 text mining을 위한 패키지로, 텍스트 분석을 위해서는 가장 먼저 소개했어야 할텐데 사용이 늦었네요. topicmodels가 오늘의 핵심, LDA 분석 함수를 담고 있습니다. LDA도 있지만, 차이가 좀 있고 사용성 면에서는 topicmodels가, 알고리즘 면에서는 LDA가 좀 더 나은 면이 있습니다. LDAvis는 LDA의 결과를 시각화하는 도구이며, Rmpfr은 정교한 floating point number 연산을 지원합니다. 나중에 Topic 수 결정을 위해서 사용하게 됩니다.
library(stringi)
library(stringr)
library(tidyverse)
library(tidytext)
library(KoNLP)
library(ggplot2)
library(lubridate)
library(tm)
library(topicmodels)
library(LDAvis)
library(Rmpfr)
자료 불러오기
이번에도 KoNLP를 사용하되, “보건 일반” 관련 사전을 사용하고, 사용자 사전을 추가하는 방식으로 접근합니다. 대상 자료는 지난번에 수집해놓은 상담 자료를 다시 활용하였습니다.
dics <- c('sejong, woorimalsam')
category <- c('health general')
user_d <- data.frame(term=c("치과", "레진", "임플란트", "사랑니", "보철물", "치석", "재치료", "이메일", "틀니", "치아번호", "브릿지"), tag=rep('ncn', 11))
buildDictionary(ext_dic=dics, category_dic_nms=category, user_dic=user_d, replace_usr_dic=TRUE)
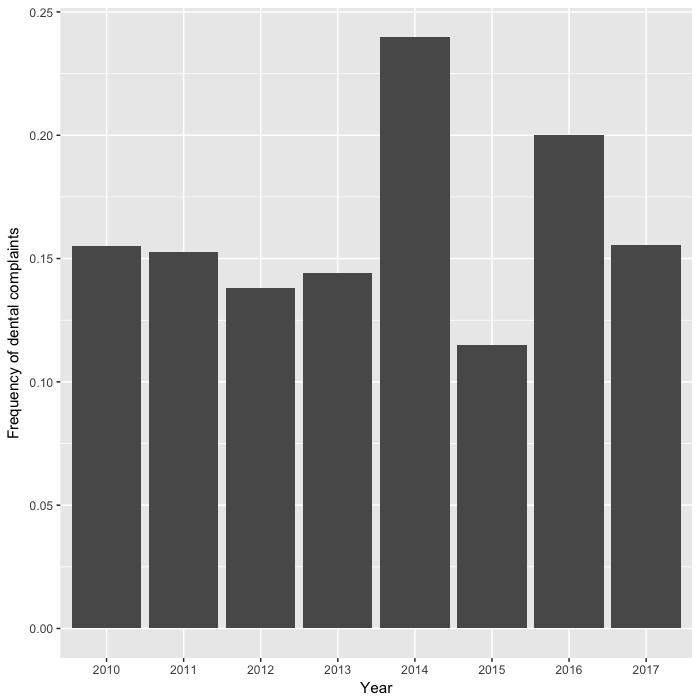
먼저 치과 관련 텍스트를 수집했습니다. 치과 관련 카테고리에 해당하는 텍스트를 모아, 자료의 분포를 확인해 보았습니다. 2014년에 급등했지만, 의료 관련 상담에서 평균적으로 15% 정도를 차지하고 있네요. 시장 점유율(?)을 생각하면, 상당한 비율이라고 생각됩니다.
articles$rec <- ymd(articles$rec)
articles$year <- year(articles$rec)
dental <- c('치과', '치아교정', '치과보증금환불', '치과병원', '임플란트 보철', '이빨', '임플란트', '치과임풀란트', '치과치료 불량', '치과진료', '페이스라인치과', '치과보철치료', '치과의료', '한울치과', '의료사고(치과)', '치과보철', '치과 보철비용', '플라스틱 치아 교정기', '치과 임프란트', '치과 교정', '치과교정', '치과 포철', '치아브릿지', '치아', '교합안정장치', '충치 치료')
dental_df <- articles %>%
filter(cat %in% dental)
table(dental_df$cat)
##
## 교합안정장치 의료사고(치과) 이빨
## 1 1 2
## 임플란트 임플란트 보철 충치 치료
## 12 1 1
## 치과 치과 교정 치과 보철비용
## 249 1 1
## 치과 임프란트 치과교정 치과병원
## 1 2 1
## 치과보증금환불 치과보철 치과보철치료
## 1 1 1
## 치과의료 치과임풀란트 치과진료
## 1 1 2
## 치과치료 불량 치아 치아교정
## 1 1 2
## 치아브릿지 페이스라인치과 플라스틱 치아 교정기
## 1 1 1
## 한울치과
## 1
dental_df$rec <- ymd(dental_df$rec)
dental_df$year <- year(dental_df$rec)
ggplot(data=as.data.frame(table(dental_df$year)/table(articles$year)), aes(x=Var1, y=Freq)) +
geom_bar(stat='identity') +
labs(x="Year", y="Frequency of dental complaints")
텍스트 전처리
먼저 필요한 오타를 정리하고 몇 가지 단어는 통일한 뒤, 숫자와 인터넷 주소를 제외시켰습니다. 자모로만 표현한 경우(ㅋㅋ, ㅜㅜ 등) 이모티콘으로 변경하였습니다. 다음, KoNLP의 SimplePos22() 함수를 통해 형태소 분석을 한 뒤, [지난 번]처럼 체언과 용언 만을 추출합니다.
question <- as.character(unique(dental_df$main))
question <- str_replace_all(question, "[[:punct:]]", "") %>%
str_replace_all("[임|인][플|풀|프][란|런|랜]트", "임플란트") %>%
str_replace_all("스[켈|케일|캘]링", "스케일링") %>%
str_replace_all("레진(치료)*", "레진") %>%
str_replace_all("어금[이|니]", "어금니") %>%
str_replace_all("손해자", "피해자") %>%
str_replace_all("[0-9]+번", "치아번호 ") %>%
str_replace_all("의사[선생]*[님]*", "의사") %>%
str_replace_all("치아교정", "교정") %>%
str_replace_all("없읍", "없습") %>%
str_replace_all("[0-9]+", " ") %>%
str_replace_all("\\s+", " ") %>%
str_replace_all("http[a-zA-Z0-9]+", "") %>%
str_replace_all("[ㄱ-ㅎㅏ-ㅣ]+", "이모티콘")
ko_words <- function(doc) {
d <- as.character(doc)
pos <- unlist(SimplePos22(d))
extracted <- str_match(pos, '([가-힣]+)/[NP][A-Z]')
keyword <- extracted[, 2]
keyword[!is.na(keyword)]
}
pos <- Map(ko_words, question)
다음, tm의 DocumentTermMatrix()를 통해 Document-Term Matrix를 계산합니다. 이때 불용어로 “치과”, “치료” 등을 제외시켰는데, 이것은 다른 단어에 비해 압도적으로 빈도가 높은 단어가 있으면 분포가 그 쪽으로 쏠리기 때문입니다. 이 단어들은 거의 모든 텍스트에 등장하기 때문에 제외시켰습니다. 또, 두 글자 미만, 또는 열 글자 이상의 단어는 제외시켰습니다. weighting=weightTf는 term frequency, 즉 텍스트에서 단어 출현 빈도로 document-term matrix를 구축하도록 합니다.
corpus <- Corpus(VectorSource(pos))
stopWords <- c("치과", "치료", "치아", "병원", "만원")
dtm <- DocumentTermMatrix(corpus, control=list(
removePunctuation=TRUE, stopwords=stopWords,
removeNumbers=TRUE, wordLengths=c(4, 20), weighting=weightTf))
기초 LDA 분석
먼저 간단하게 LDA 분석 결과를 확인하기 위하여, tidytext 패키지와 결합하여 어떤 방식으로 결과가 나오는지 살펴보겠습니다. 먼저, topicmodels의 LDA 함수로 텍스트를 분류합니다. k는 텍스트를 몇 개의 집단으로 나눌 것인지 정하는 사전변수입니다. 먼저, 두 집단으로 나눠서 결과를 볼게요.
q_lda <- LDA(dtm, k=2, seed=1234)
q_topics <- tidy(q_lda, matrix="beta")
q_top_terms <- q_topics %>%
group_by(topic) %>%
top_n(10, beta) %>%
ungroup() %>%
arrange(topic, -beta)
q_top_terms %>%
mutate(term=reorder(term, beta)) %>%
ggplot(aes(term, beta, fill=factor(topic))) +
geom_col(show.legend=FALSE) +
facet_wrap(~ topic, scales="free") +
coord_flip() +
theme(axis.text.y=element_text(family="Apple SD Gothic Neo"))
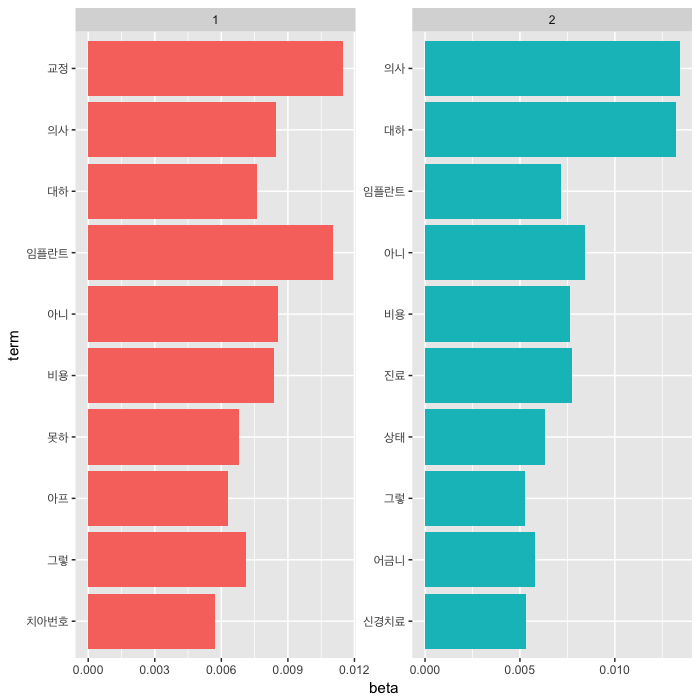
두 집단으로 나눠본 결과, 비슷하게 등장하는 단어들을 빼면 topic 1에는 교정, 임플란트가, topic 2에는 의사, 대하(다)가 눈에 띄네요. 위의 결과는 각 집단에서 가장 출현확률(beta)이 높은 단어를 모은 방식입니다. 이번에는, 두 집단 출현확를의 차이로 나열해 보겠습니다.
beta_spread <- q_topics %>%
mutate(topic=paste0("topic", topic)) %>%
spread(topic, beta) %>%
filter(topic1 > .001 | topic2 > .001) %>%
mutate(log_ratio=log(topic2 / topic1))
bind_rows(beta_spread %>% top_n(-10, log_ratio), beta_spread %>% top_n(10, log_ratio)) %>%
ggplot(aes(reorder(term, log_ratio), log_ratio)) +
geom_col(show.legend=FALSE) +
labs(x="term", y="Log2 ratio of beta in topic 2 / topic 1") +
coord_flip() +
theme(axis.text.y=element_text(family="Apple SD Gothic Neo"))
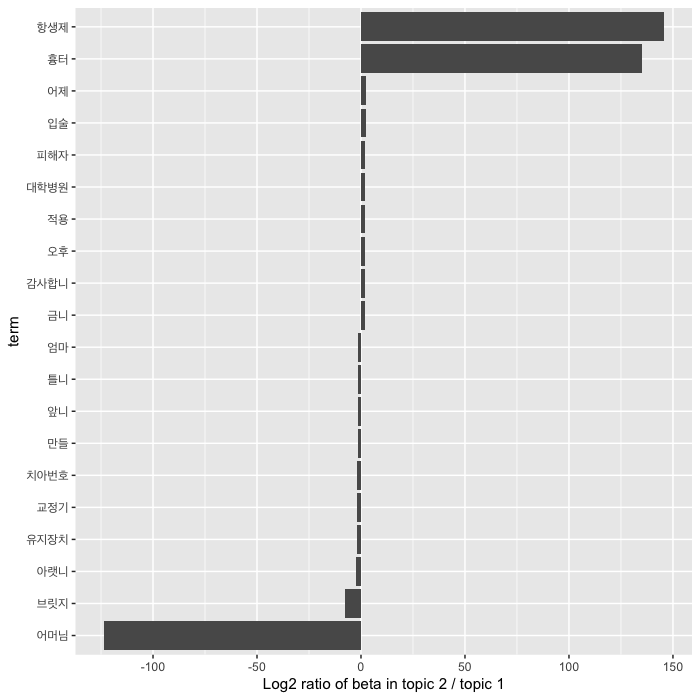
두 집단에서 출현확률의 차이로 비교해보면, topic 1은 어머님, 브릿지가, topic 2는 항생제, 흉터가 중요하게 나타납니다. 위의 결과와 종합하여 생각해보면, topic 1은 진료 관련 상담, topic 2는 진료 서비스 및 후유증 등에 관한 상담인 것으로 생각해볼 수 있습니다. 실제로 각 텍스트가 어느 집단으로 분류되었는지 볼까요?
q_documents <- tidy(q_lda, matrix="gamma")
q_documents
## # A tibble: 564 × 3
## document topic gamma
## <chr> <int> <dbl>
## 1 1 1 0.0010958588
## 2 2 1 0.0014860737
## 3 3 1 0.9997471939
## 4 4 1 0.9986573537
## 5 5 1 0.9983361908
## 6 6 1 0.0015409439
## 7 7 1 0.0004532204
## 8 8 1 0.0001689069
## 9 9 1 0.0013872770
## 10 10 1 0.7181085591
## # ... with 554 more rows
tidy(dtm) %>%
filter(document == 8) %>%
arrange(desc(count))
## # A tibble: 173 × 3
## document term count
## <chr> <chr> <dbl>
## 1 8 수술 12
## 2 8 아버지 5
## 3 8 의사 5
## 4 8 진료 5
## 5 8 금액 4
## 6 8 보호자 4
## 7 8 안하 4
## 8 8 지불 4
## 9 8 거부 3
## 10 8 당일 3
## # ... with 163 more rows
처음 10개의 문서 중 topic 1일 가능성이 가장 낮은 문서 8번을 보면, 수술, 아버지, 의사, 진료, 금액 등의 단어로 구성되어 있습니다. 아버지의 치과 수술 관련한 비용 상담인 것을 확인해볼 수 있습니다.
이어, 네 개의 집단으로 나눠보겠습니다.
q2_lda <- LDA(dtm, k=4, seed=1234)
q2_topics <- tidy(q2_lda, matrix="beta")
top_terms <- q2_topics %>%
group_by(topic) %>%
top_n(7, beta) %>%
ungroup() %>%
arrange(topic, -beta)
top_terms %>%
mutate(term=reorder(term, beta)) %>%
ggplot(aes(term, beta, fill=factor(topic))) +
geom_col(show.legend=FALSE) +
theme(axis.text.y=element_text(family="Apple SD Gothic Neo")) +
facet_wrap(~ topic, scales="free") +
coord_flip()
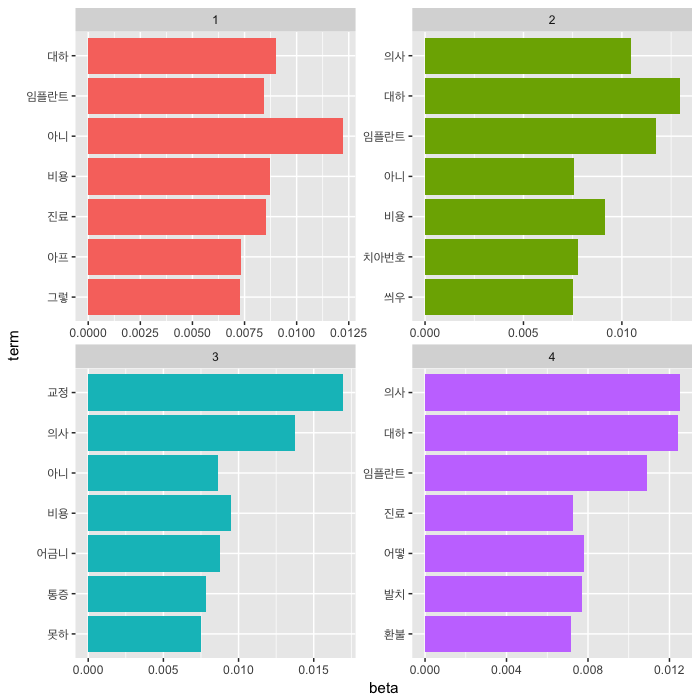
네 개의 topic으로 분류하여 주요 단어 7개를 나열해 보았습니다. topic 1은 아니(다), 대하(다), 비용 등이, topic 2는 대하(다), 임플란트, 의사가, topic 3은 교정, 의사, 비용이, topic 4는 의사, 대하(다), 임플란트 등이 중요 단어로 나타나네요. 어느 정도는 topic이 짐작되지만 정확히 확인하기는 어렵죠. 따라서, 실제로 문헌 분석을 위해서 Jacobi 등은 topic browser를 만들어서 활용할 것을 권하고 있습니다. Topic brower란, topic의 중요 단어와 가장 일치도가 높은 텍스트를 같이 보면서 해당 topic의 주제를 추측할 수 있도록 하는 방식을 의미합니다.
K값 정하기와 LDAvis
여기까지 보셨으면 LDA를 위해 K값, 즉 집단의 갯수를 정해주어야 한다는 것을 아셨을 겁니다. k-means clustering과 비슷하죠. 그리고 분류 갯수 결정의 최적화 방식은 아직 의견이 분분합니다. 보통은 2부터 4, 50개까지, 대규모 자료의 경우는 100~200개까지 분류해보고 log likelihood 값의 harmonic mean이 최대가 되는 K값, 또는 perplexity 값의 변화가 최소가 되는 지점(RPC: Rate of perplexity change)의 K값을 사용합니다. 여기에서는 harmonic mean을 구해 K값을 결정합니다. 2~40개의 K 값으로 LDA를 구하며, 이때 Gibbs sampling 방식으로 모형을 구축해 볼 것입니다. Gibbs sampling은 간단히 말하면 변수를 하나씩 바꿔가면서 표본을 수집하여 모형을 근사하는 방식입니다. 이때, burnin은 처음부터 burnin에 지정한 값까지는 제외시키고 나머지 값만을 모형 근사에 사용하겠다는 선언이며, iter는 몇 개까지 표본을 수집할지를, keep은 정한 값마다 log likelihood 값을 구해서 저장하도록 설정하는 변수입니다. 이 시도를 통해 구한 log likelihood 값의 최빈값을 통해 harmonic mean을 구하는 방식은 Ponweiser의 논문에 정리되어 있습니다.
harmonicMean <- function(logLikelihoods, precision=2000L) {
llMed <- median(logLikelihoods)
as.double(llMed - log(mean(exp(-mpfr(logLikelihoods,
prec=precision) + llMed))))
}
seqk <- seq(2, 40, 1)
burnin <- 1000
iter <- 1000
keep <- 50
fitted_many <- lapply(seqk, function(k) LDA(dtm, k=k, method="Gibbs", control=list(burnin=burnin, iter=iter, keep=keep)))
logLiks_many <- lapply(fitted_many, function(L) L@logLiks[-c(1:(burnin/keep))])
hm_many <- sapply(logLiks_many, function(h) harmonicMean(h))
Update: 10/10/17, harmonic mean 계산 function 과 관련 변수 설정 코드 추가
ggplot(data.frame(seqk, hm_many), aes(x=seqk, y=hm_many)) +
geom_path(lwd=1.5) +
theme(text=element_text(family=NULL),
axis.title.y=element_text(vjust=1, size=16),
axis.title.x=element_text(vjust=-.5, size=16),
axis.text=element_text(size=16),
plot.title=element_text(size=20)) +
xlab('Number of Topics') +
ylab('Harmonic Mean') +
ggplot2::annotate("text", x=9, y=-199000, label=paste("The optimal number of topics is", seqk[which.max(hm_many)])) +
labs(title="Latent Dirichlet Allocation Analysis",
subtitle="How many distinct topics?")
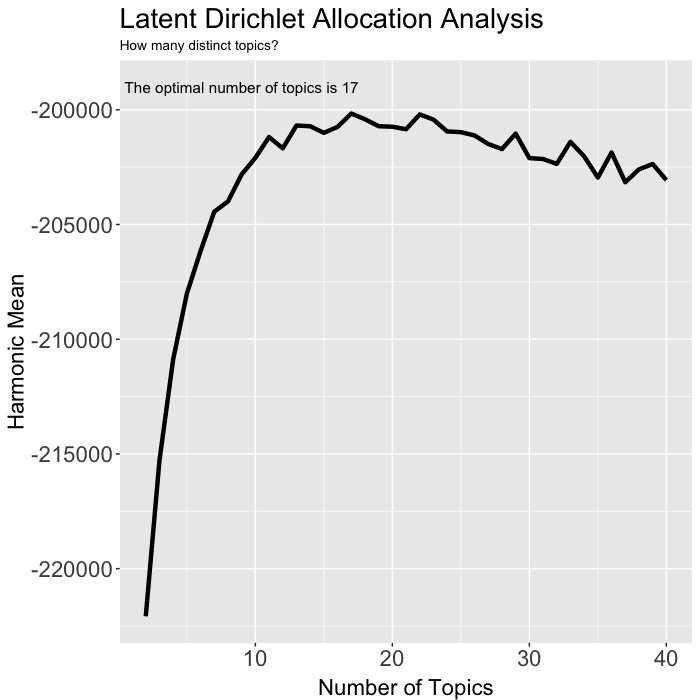
17에서 harmonic mean이 최대로 나오네요. K=17로 모형을 구축해 볼까요?
q_model <- LDA(dtm, k=17, method="Gibbs", control=list(iter=2000))
q_topics <- topics(q_model, 1)
q_terms <- as.data.frame(terms(q_model, 20), stringsAsFactors=FALSE)
q_terms[1:5]
## Topic 1 Topic 2 Topic 3 Topic 4 Topic 5
## 1 교정 이빨 저희 전화 레진
## 2 그렇 앞니 못하 환자 떨어지
## 3 시간 본인 어떻 못하 붙이
## 4 기다리 설명 돌리 연락 다르
## 5 진료 비용 안되 안되 시리
## 6 장치 방법 오늘 안녕 나중
## 7 끝나 브릿지 어머니 바뀌 피해자
## 8 교정기 비싸 다르 예약 부위
## 9 얘기 생각 엄마 모르 피하
## 10 때문 정도 손상 사람 벌어지
## 11 유지장치 느끼 어머님 이야기 유디치과
## 12 사람 자기 진료 원장님 조금씩
## 13 정도 원장 소개 실장 철사
## 14 문제 윗니 치료후 요청 재치료
## 15 환불 아랫니 현금 원장 부탁드립니
## 16 이해 태도 계약금 내원 아이
## 17 본인 고르 삽입 내용 나가
## 18 교정장치 불편 알리 입장 첨부
## 19 근데 잘못 무료 아니 치료전
## 20 착용 때문 그렇 다니 동안
topic 1~5의 중심 단어를 나열해 보았습니다. topic 1은 임플란트 수술 관련, topic 2는 비용 상담 관련, topic 3은 충치와 교정치료 관련, topic 4는 치료 통증 관련, topic 5는 진료 상담 관련 내용인 것으로 추측해볼 수 있겠네요. 이제, 시각화를 위해 LDAvis 패키지를 사용해 볼 것입니다. LDAvis 사용을 위해서는 phi, theta, vocab, doc.length, term.frequency list를 만들어서 createJSON 함수에 넣어준 다음, serVis 함수를 적용하면 지정한 폴더에 결과가 저장됩니다.
K <- 17
G <- 5000
alpha <- 0.02
fit <- LDA(dtm, k=K, method='Gibbs', control=list(iter=G, alpha=alpha))
phi <- posterior(fit)$terms %>% as.matrix
theta <- posterior(fit)$topics %>% as.matrix
vocab <- colnames(phi)
doc_length <- c()
for(i in 1:length(corpus)) {
temp <- paste(corpus[[i]]$content, collapse=" ")
doc_length <- c(doc_length, stri_count(temp, regex='\\S+'))
}
temp_frequency <- as.matrix(dtm)
freq_matrix <- data.frame(ST=colnames(temp_frequency),
Freq=colSums(temp_frequency))
rm(temp_frequency)
json_lda <- createJSON(phi=phi,
theta=theta,
vocab=vocab,
doc.length=doc_length,
term.frequency=freq_matrix$Freq)
serVis(json_lda, out.dir='2017-08-15-complaint-vis', open.browser=FALSE)
결과를 볼까요? 2017-08-15-complaint-vis/index.html입니다.
왼쪽에는 topic의 분포와 상대적인 거리가, 오른쪽에는 각 topic의 중심 단어 및 전체 출현 숫자에서의 비율이 표시됩니다. 먼저 2017-08-15-complaint-vis/index.html#topic=1&lambda=1&term=를 보면, 전체의 절반 가까운 텍스트가 하나의 topic으로 분류된 것을 확인할 수 있습니다. 단어 분포를 보니 의사의 태도 및 치료 비용 관련 상담, 즉 진료 서비스 관련 문제 제기인 것으로 보이네요. 전체 상담의 절반을 차지하고 있는 것에 주목할 필요가 있을 것 같습니다.
다음은 전체의 5% 정도를 각각 차지하는 topic 2, topic 3입니다. topic 2는 신경치료 등에서 발생한 통증 관련 상담, topic 3는 교정 장치 및 유지장치 관련 상담이네요.
나머지 14개의 topic은 상대적 거리가 근접해 있습니다. 워낙 topic 1, 2, 3이 두드러져서 그렇기도 할 것이고, 치료 관련 상담에서 주제가 편중되는 것은 어찌보면 당연할 것 같아요. 커서를 원 위에 올리면 해당 topic의 주제어들을 확인하실 수 있습니다.
마치며
이번에는 치과 불만 상담 관련하여 자료를 살펴보고, 비지도 학습 방법인 LDA로 분류하여 각 topic의 주제를 분석해 보았습니다. 치과가 전체 의료 불만 상담의 15%를 차지하며, 그 절반이 서비스(‘의사’가 ‘대하’는 방식, ‘비용’ 관련하여 ‘못하’거나/겠다는 표현–아마 치료가 잘못되었거나 치과와 분쟁 조정이 잘 이뤄지지 않은 것을 의미하는 것 같습니다–이 주로 등장하는) 관련 이라는 것에 관해 좀 더 곰곰히 생각해 볼 필요가 있을 것 같습니다. 다음 번에는, 의과와 치과가 어떻게 차이가 나는지 확인해 볼게요.
Comments