Grad CAM으로 딥 러닝 모형 해석 (R version)
여러 곳에서 딥 러닝을 활용하고 있는 상황이지만, 개인적으로는 집중해서 매달리지는 않는 편입니다. 가장 큰 이유는 제가 관심 있는 것이 분석 결과가 아니라 해석이기 때문일 텐데요. 학문적 관심으로 접근하는 입장에서 딥러닝이 내는 좋은 결과도 해석하지 못하면 저에게는 크게 다가오지 않는 것 같습니다. 다행인 것은, 최근 머신 러닝 모형 해석을 위한 여러 가지 방법들이 제시되고 있다는 것이죠.
Attention mechanism과 lime 패키지( python, R )가 대표적인 예였던 것 같아요. Attention mechanism은 딥 러닝 모형이 가중치를 두고 살피는 부분이 어디인지를 알려주는 방법이었죠 ( Attention and Memory in Deep Learning and NLP ). 이미지의 경우 어떤 지점을, 텍스트의 경우 어떤 단어를 모형이 중요하게 다루는지를 알려주었고요. 단, 모형에 구조가 추가된다는 것, 여전히 관심 지점이 어떤 식으로 작용하는지는 알기 어렵다는 단점이 있었습니다.
LIME(Local Interpretable Model-agnostic Explanations)는 완성된 딥 러닝 모형에 feature 일부만을 적용한 결과를 통해, 예측에 해당 feature가 얼마나 영향을 미치는지 제시하는 방법이었죠. Random forest 모형 해석에 적용한 예시는 훌륭했지만, 딥 러닝에 적용한 사례( LIME )에서, 방법론의 명칭 자체에서 볼 수 있는 것처럼 model-agnostic (모형에 관해서는 알 수 없음) 하다는 점, LIME이 결과로 제출하는 linear model이 가장 단순한 모형을 도출하기 때문에 사용되는 feature가 들쭉날쭉 하다는 것은 여전히 한계였던 것 같아요.
최근 발표된 Selvaraju RR 등의 Grad CAM (Gradient-weighted Class Activation Mapping, arxiv )은 CNN 모형에 적용할 수 있는 모형 해석 방법론입니다. 쉽게 설명하면 CNN 층(마지막)에 들어가는 그래디언트를 가지고 자료의 어느 부분에 가중치를 주는지 계산하는 방법이 될 것 같습니다. 별다른 구조 변경이나 재훈련 없이 바로 적용해볼 수 있다는 점, CNN이 사용되는 영역이 무척 넓다는 점(제가 주로 관심을 가지고 있는 텍스트 분석에도 마찬가지죠)이 매력적인 것 같아요.
이번 포스트는 전희원님의 포스트( Grad CAM을 이용한 모형 해석 )를 그저 R 코드로 다시 refactoring 한 것입니다. 부가적인 설명은 원 포스트를 참고해 주세요. 저 같이 모형 해석에 관심이 더 있으실 R 사용자분들이 계실까 하여 올려봅니다.
Code
먼저 사용한 라이브러리와 자료입니다. Naver Sentiment Movie Corpus 를 이용했습니다. 형태소 분석에는 RmecabKo를 사용했습니다.
# devtools::install_github("junhewk/RmecabKo")
# 추가적인 설치 방법은 https://github.com/junhewk/RmecabKo 를 참고해주세요.
library(RmecabKo)
library(tidyverse)
library(tidytext)
library(stringr)
library(keras)
tbl <- read.csv("ratings_train.txt", sep = "\t", stringsAsFactors = FALSE)
glimpse(tbl)
## Observations: 150,000
## Variables: 3
## $ id <int> 9976970, 3819312, 10265843, 9045019, 6483659, 5403919, 7797314, 9443947, 7156791, 5912145, 9008700, 10217543, 5957425, 8628627, ...
## $ document <chr> "아 더빙.. 진짜 짜증나네요 목소리", "흠...포스터보고 초딩영화줄....오버연기조차 가볍지 않구나", "너무재밓었다그래서보는것을추천한다", "교도소 이야기구먼 ..솔직히 재미는 없다..평점 조정", "사이몬페그의 익살스런 연...
## $ label <int> 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1,...
Training set 구축을 위해 텍스트를 (1) 형태소 분석, (2) 빈도 상위 5000개 단어 추리기, (3) ‘_PAD_’ (sequence 만들 때, 길이를 맞추는 데 쓰는 빈 공간 token) 와 ‘_UNK_’ (분석에 포함하지 않는 token) 추가, (4) which 와 keras::pad_sequences 함수를 통해 id list로 텍스트를 변환하는 과정을 거쳤습니다.
tbl <- tbl %>%
mutate(document = str_trim(document, "both")) %>%
mutate(keywords = token_morph(document, strip_punct = FALSE))
keyword_cnt <- as.data.frame(table(unlist(tbl$keywords)))
keyword_clip <- keyword_cnt %>%
as.tibble() %>%
arrange(desc(Freq)) %>%
head(5000) %>%
set_names(c("keyword", "n")) %>%
select(-n)
keyword_clip <- bind_rows(keyword_clip,
data_frame(keyword = c('_PAD_', '_UNK_'))) %>%
mutate(id = row_number())
max_seq <- median(do.call(rbind, lapply(tbl$keywords, length))) + 5
train_x <- lapply(tbl$keywords,
function(x) as.list(match(x, keyword_clip$keyword,
nomatch = filter(keyword_clip, keyword == "_UNK_")$id))) %>%
pad_sequences(maxlen = max_seq, padding = 'pre', truncating = 'pre',
value = filter(keyword_clip, keyword == "_PAD_")$id)
train_y <- tbl$label
분석에 사용할 CNN 모형입니다. 세 층의 Convolution Layer를 결합하고 위에 GRU Layer를 bidirectional로 쌓았습니다.
x_dim <- dim(train_x)[2]
input_txt <- layer_input(shape = c(x_dim), name = 'input')
embeddings_out <- input_txt %>%
layer_embedding(input_dim = nrow(keyword_clip) + 1, output_dim = 50, name = 'embedding')
conv_1 <- embeddings_out %>%
layer_conv_1d(32, 1, padding = 'same') %>%
layer_average_pooling_1d()
conv_2 <- embeddings_out %>%
layer_conv_1d(16, 2, padding = 'same') %>%
layer_average_pooling_1d()
conv_3 <- embeddings_out %>%
layer_conv_1d(8, 3, padding = 'same') %>%
layer_average_pooling_1d()
concat <- layer_concatenate(c(conv_1, conv_2, conv_3), axis = 2)
bidir <- concat %>%
bidirectional(layer_gru(units = 10, recurrent_dropout = 0.2, dropout = 0.2))
output <- bidir %>%
layer_dense(1, activation = 'sigmoid')
model <- keras_model(inputs = input_txt, outputs = output)
model %>%
summary()
## ________________________________________________________________________________
## Layer (type) Output Shape Param # Connected to
## ================================================================================
## input (InputLayer) (None, 19) 0
## ________________________________________________________________________________
## embedding (Embedding) (None, 19, 50) 250150 input[0][0]
## ________________________________________________________________________________
## conv1d_1 (Conv1D) (None, 19, 32) 1632 embedding[0][0]
## ________________________________________________________________________________
## conv1d_2 (Conv1D) (None, 19, 16) 1616 embedding[0][0]
## ________________________________________________________________________________
## conv1d_3 (Conv1D) (None, 19, 8) 1208 embedding[0][0]
## ________________________________________________________________________________
## average_pooling1d_1 (Aver (None, 9, 32) 0 conv1d_1[0][0]
## ________________________________________________________________________________
## average_pooling1d_2 (Aver (None, 9, 16) 0 conv1d_2[0][0]
## ________________________________________________________________________________
## average_pooling1d_3 (Aver (None, 9, 8) 0 conv1d_3[0][0]
## ________________________________________________________________________________
## concatenate_1 (Concatenat (None, 9, 56) 0 average_pooling1d_1[0][0]
## average_pooling1d_2[0][0]
## average_pooling1d_3[0][0]
## ________________________________________________________________________________
## bidirectional_1 (Bidirect (None, 20) 4020 concatenate_1[0][0]
## ________________________________________________________________________________
## dense_1 (Dense) (None, 1) 21 bidirectional_1[0][0]
## ================================================================================
## Total params: 258,647
## Trainable params: 258,647
## Non-trainable params: 0
## ________________________________________________________________________________
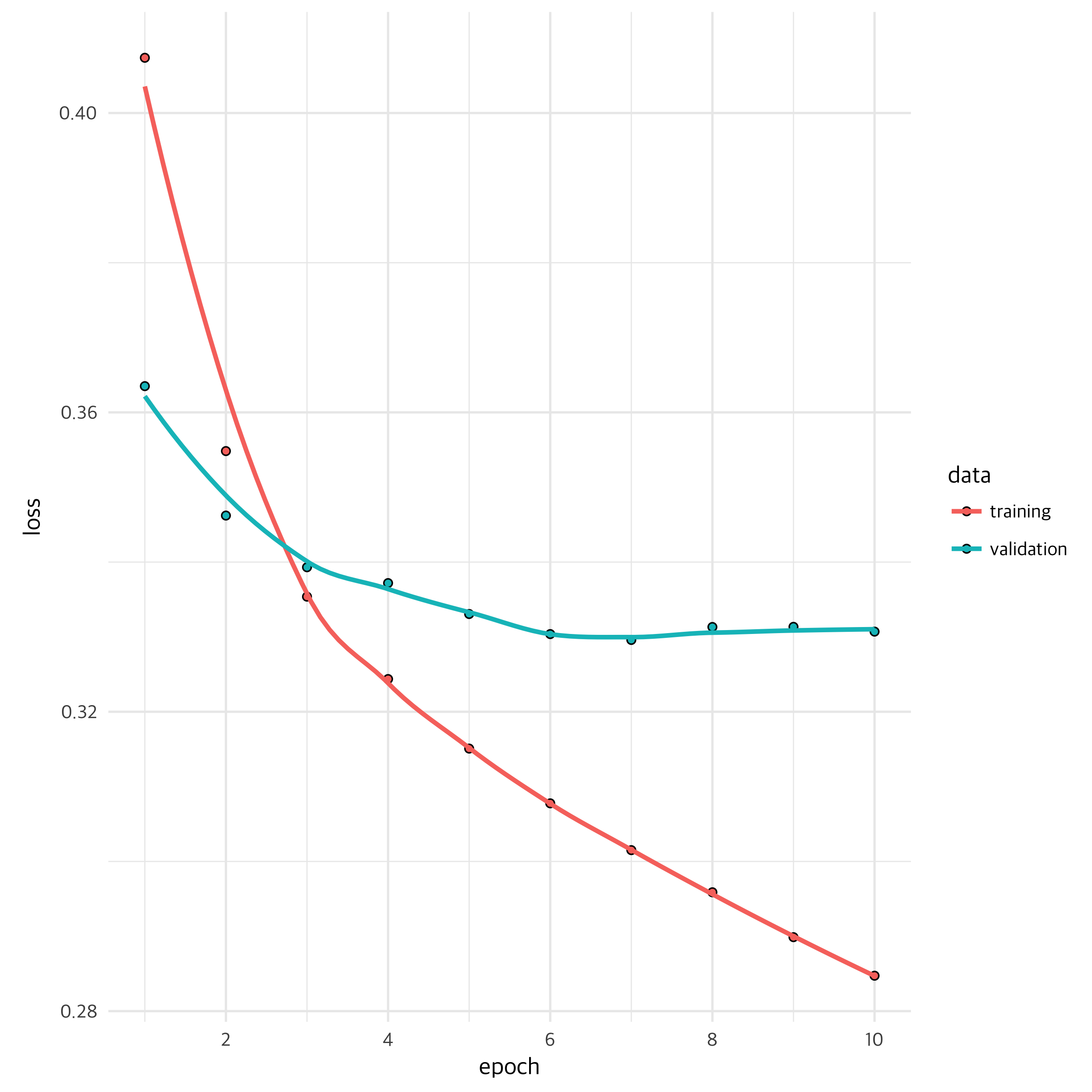
모형 훈련 과정입니다. mini batch 100개씩 해서 10회 반복하여 훈련시켰고, 슬슬 낡아가고 있는 제 컴퓨터에서도 그리 긴 시간은 걸리지 않았습니다. Validation이 적당히 내려가면서 training도 적절히 되고 있는 모습을 보여주네요.
model %>%
compile(optimizer = 'rmsprop', loss = 'binary_crossentropy')
hist <- model %>%
fit(x = train_x,
y = train_y,
batch_size = 100,
epochs = 10,
validation_split = 0.1)
plot(hist)
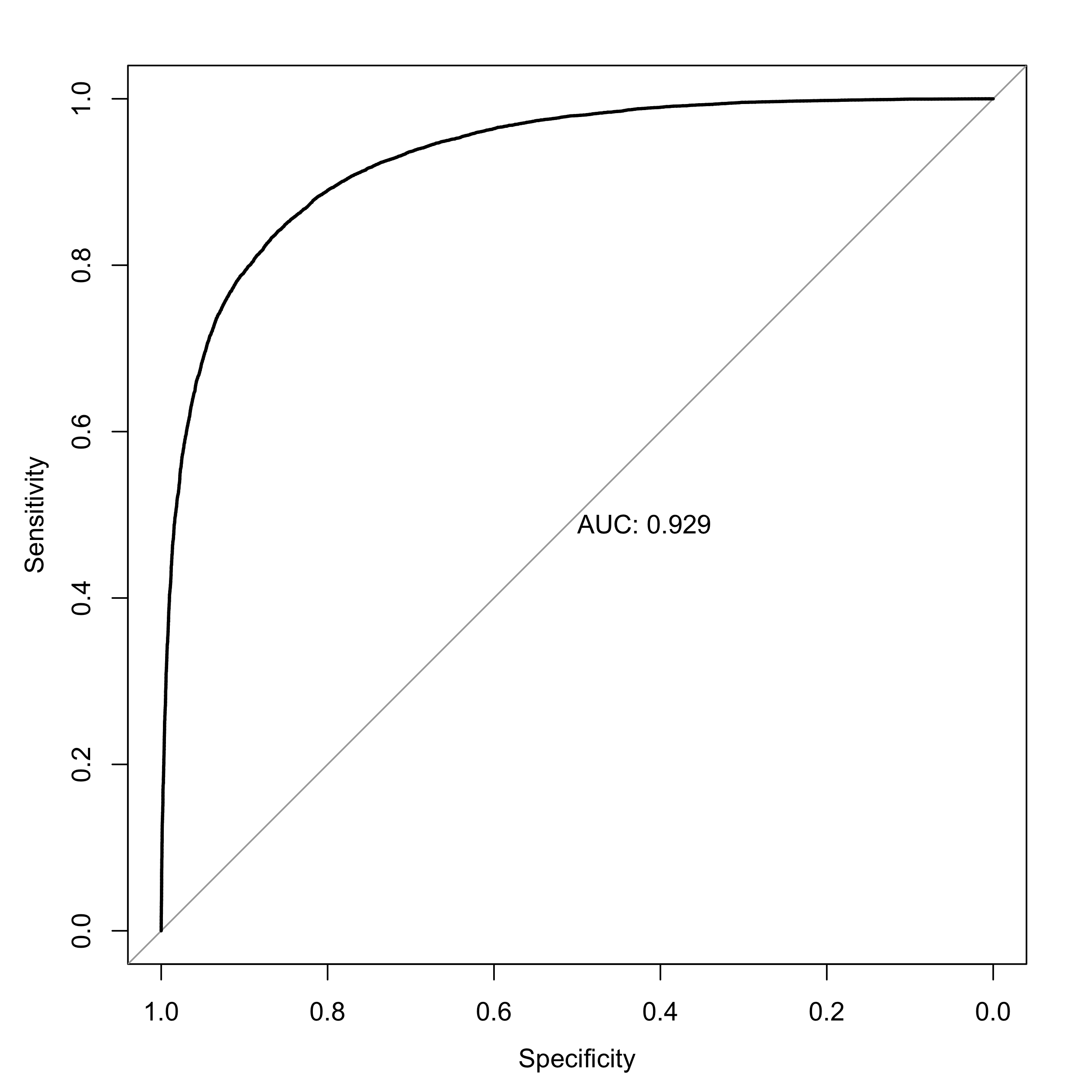
Test set을 불러와서 ROC 커브를 그려보았습니다. 0.93이면 괜찮은 것 같아요.
tbl_test <- read.csv("ratings_test.txt", sep = "\t")
tbl_test <- tbl_test %>%
mutate(document = str_trim(document, "both")) %>%
mutate(keywords = token_morph(document))
test_x <- lapply(tbl_test$keywords, function(x) as.list(match(x, keyword_clip$keyword, nomatch = filter(keyword_clip, keyword == "_UNK_")$id))) %>%
pad_sequences(maxlen = max_seq, padding = 'pre', truncating = 'pre', value = filter(keyword_clip, keyword == "_PAD_")$id)
test_y <- tbl_test$label
dim(test_x)
## [1] 50000 19
prob <- model %>%
predict(test_x)
library(pROC)
plot(roc(test_y, prob), print.auc = TRUE)
이번 포스트의 핵심인 Grad CAM 함수입니다. 모형에서 원하는 layer의 정보(가중치)를 가져옵니다. 다음, output -> 해당 신경층까지의 그래디언트를 가져왔어요(grads). 이어서 평균으로 합친 다음 (pooled_grads), 훈련에 사용했던 자료를 넣어서 필터의 가중치를 구합니다.
grad_cam_conv1D <- function(target_model, layer_nm, x, sample_weight = 1, keras_phase = 0) {
layers <- target_model %>% get_layer(layer_nm)
layers_wt <- layers$weights
layers_weights <- layers$get_weights()
grads <- k_gradients(target_model$output[, 1], layers_wt)[[1]]
pooled_grads <- k_mean(grads, axis = c(1, 2))
get_pooled_grads <- k_function(list(target_model$input, target_model$sample_weights[[1]], k_learning_phase()),
list(pooled_grads, layers$output))
value <- get_pooled_grads(list(list(x), list(sample_weight), keras_phase))
for (i in seq(1, dim(value[[2]])[length(dim(value[[2]]))], 1)) {
value[[2]][, , i] = value[[2]][, , i] * value[[1]][i]
}
heatmap <- apply(value[[2]], 2, mean)
return(heatmap)
}
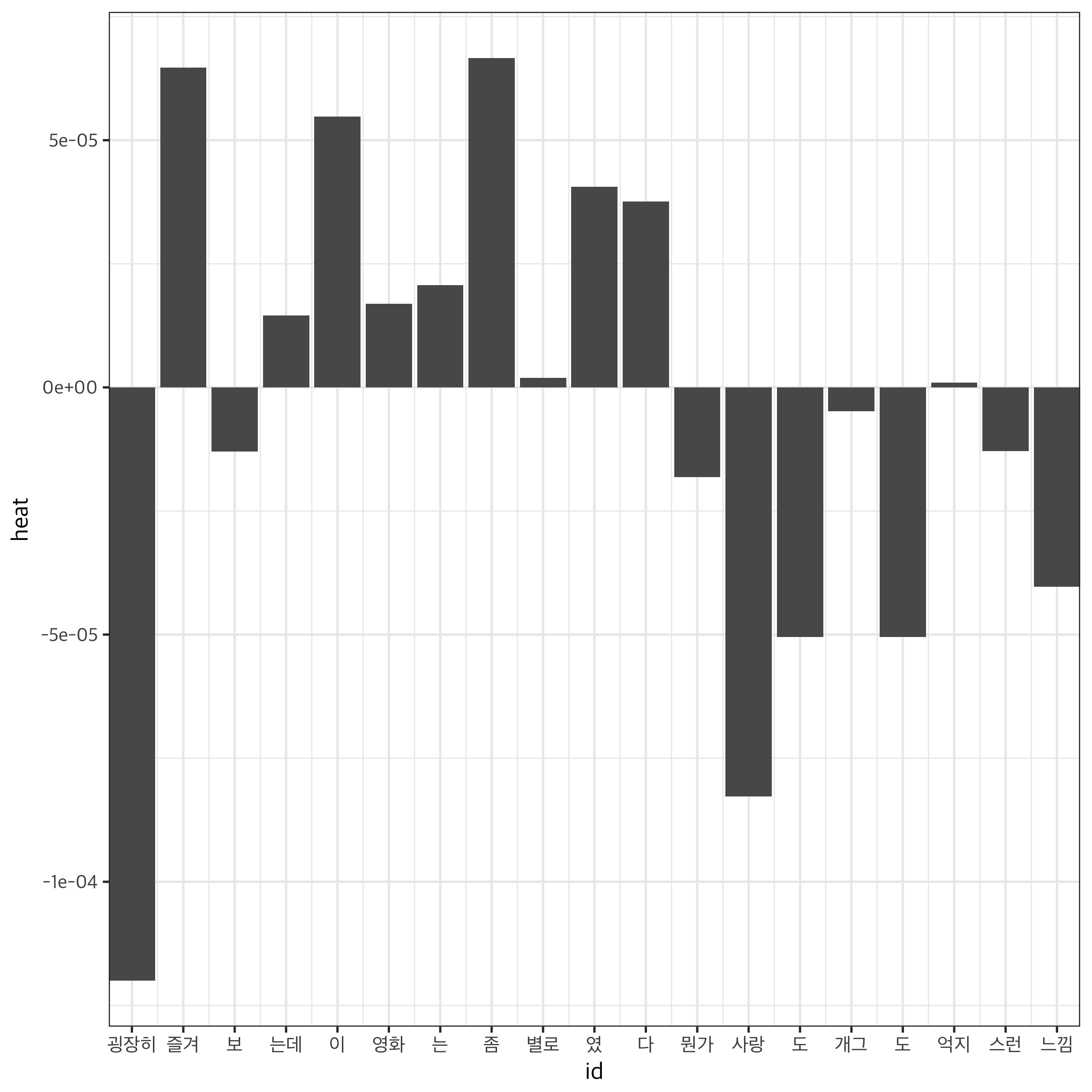
91번 자료를 통해 각 token의 가중치를 확인해 보았습니다. “굉장히”, “사랑”, “도”, “느낌”이 결과를 부정적으로 판정하는데, “즐겨”, “이”, “좀”, “였”, “다”는 결과를 긍정적으로 판정하는 데 기여했네요. 최종적으로 부정적인 리뷰로 판정되었습니다만, 평소에 생각하던 것과는 상당히 다른 결과라서 흥미로운 것 같아요. 다른 자료로 더 살펴봐야 겠네요.
tbl_test$document[91]
## [1] "로코 굉장히 즐겨보는데, 이 영화는 좀 별로였다. 뭔가 사랑도 개그도 억지스런 느낌.."
hw <- grad_cam_conv1D(model, 'conv1d_1', x = test_x[91, ])
hm_tbl <- keyword_clip[test_x[91, ], 1] %>%
bind_cols(data_frame(heat = hw)) %>%
mutate(id = row_number())
ggplot(hm_tbl, aes(x = id, y = heat)) +
geom_bar(stat = 'identity') +
theme_bw(base_family = "Apple SD Gothic Neo") +
scale_x_continuous(
breaks = hm_tbl$id,
labels = hm_tbl$keyword,
expand = c(0, 0)
)
마치며
전희원님도 말씀하고 계시지만 이 방법을 통해 긍정, 부정 단어 사전을 구축할 수 있겠다는 생각을 해봅니다. 랜덤 샘플링을 하면 여러 단어의 가중치를 구해서, 거꾸로 각 단어가 해당 corpus의 결과에 어떤 영향을 미치는지를 생각해 볼 수 있겠죠. 이렇게 다시 한 번 한국어 감정 사전의 꿈을 꿔봅니다만, 언제 할 지는 모르겠네요.
좋은 포스트에 사족을 하나 붙였습니다. 다시 한 번, 좋은 내용 소개해주신 전희원님께 감사드려요. 언제나, 궁금한 점은 말씀주셔요. 같이 풀어나갔으면 좋겠습니다. 다음 포스트까지 행복하시길 바라며!
Comments