지대넓얕 팟캐스트 분석, XML parsing
팟캐스트의 대중화에 기여한 것은 2011년 딴지일보에서 제작한 나는 꼼수다였던 것으로 기억합니다. 인기였던 TV 프로그램 나는 가수다에서 제목을 빌린 이 팟캐스트는 당시 대통령에 대한 비난 여론을 집중시키는 창구 역할을 하면서, 이후 한국 정치 지형 변화의 기폭제가 되었다고 말해도 좋을 것 같습니다.
제가 처음 팟캐스트를 들었던 것은 2008년 정도부터 였던 것 같습니다. 영어 공부를 하겠다는 핑계로 당시 막 생겨나고 있던 영어 팟캐스트를 어줍잖게 듣다가 포기했었던 기억과, 2010년에 당시 미국으로 건너간 김영하 작가가 막 시작했던 김영하의 책 읽는 시간을 들으면서 신기해 했던 기억이 나네요. 해당 팟캐스트는 지금까지도 듣고 있지만, 요새 전방위로 활동하고 있는 작가의 일정 때문인지 업데이트가 뜸해서 아쉽습니다.
최근 팟빵이 유료화 정책을 시작하면서 호스팅하던 팟캐스트의 외부 접근을 차단했다는 소식을 뒤늦게야 알았습니다. 사실, 이 포스트를 준비하면서 국내 팟캐스트 자료를 분석하려다 보니 접근이 되지 않는다는 것을 알게 된 것입니다. 그 문제는 다른 각도로 생각해볼 만한 부분들이 있을 것이나, 오늘은 국내에서 인기 있는 일부 팟캐스트의 RSS를 분석해 볼 것입니다.
RSS는 뉴스, 블로그 등에서 기사의 목록을 나열하고 있는 컨텐츠 표현 방식으로, XML 마크업 기반으로 구축되어 해당 사이트에 접속하지 않아도 기사 목록 등을 확인할 수 있는 서비스를 제공합니다. 팟캐스트도 마찬가지로 RSS 형식으로 에피소드 목록을 제공합니다. R의 XML 구문 분석을 통해, 팟캐스트의 변화를 확인해보는 것도 의미 있는 작업이 되겠다는 생각이 들었습니다.
오늘 분석에 활용할 팟캐스트는 최근 성공리에 종영(?) 한 지대넓얕 또는 지적 대화를 위한 넓고 얕은 지식입니다. 2014년에 시작한 이 팟캐스트는 다양한 분야의 지식을 쉽게 설명하면서 인기를 끌고, 진행자 네 명을 유명하게 만들었죠. 이 팟캐스트와 그알싫 또는 그것은 알기 싫다, 그리고 망치부인의 시사수다를 비교해보려 합니다. 이 팟캐스트를 선정한 이유는 앞서 말씀드린 것처럼 최근 팟빵이 유료화를 선언하면서, 외부에서 RSS 접근을 막았기 때문입니다. 반면 이 팟캐스트들은 RSS 접근이 가능하거든요. 곧 마무리한다는 김어준의 파파이스를 다뤄보고 싶었는데 아쉬워요. 유튜브 플레이리스트가 있으니, 다음번에 YouTube Data API 다룰 때 분석해볼게요.
분석 코드는 XML parsing made easy: is that podcast getting longer? 포스트를 그대로 따르되, 일부만 수정한 것입니다. 원본 코드는 github에서 확인할 수 있으며, 제작자는 Neil Saunders 임을 미리 언급해둡니다.
library(tidyverse)
library(tidytext)
library(rvest)
library(lubridate)
library(knitr)
library(stringr)
library(ggplot2)
library(ggridges)
library(wordcloud)
library(wesanderson)
사용한 패키지부터 살펴보겠습니다. tidyverse와 tidytext는 기존에도 다루었으니 넘어가고, rvest를 통해 xml 불러오기와 parsing을 처리합니다. lubridate는 character 형식으로 되어 있는 시간 자료를 strptime의 복잡한 형식 입력 없이 아주 간편하게 변환해줍니다. knitr과 ggplot2는 기본인 것 같고, 오늘 시각화의 핵심은 ggridges 일 텐데요, 뒤에서 결과를 직접 보시는 게 빠를 것 같습니다. wordcloud는 어쩌다 보니 다룬 적이 없네요. 많이들 쓰실 텐데, 사용 팁을 다뤄볼 수 있을 것 같아요. wesanderson 패키지는 웨스 앤더슨 감독의 영화에서 색채를 뽑아온 color palette입니다.
XML parsing
말씀드린 대로 오늘은 팟캐스트의 RSS 파일을 불러와서 분석해볼 것입니다. 예를 들어, 2008년부터 방송을 진행해오고 있는 (그리고 원 포스트의 분석 대상인) This Week in Virology 팟캐스트 RSS를 불러오는 과정을 한번 볼까요?
feed_items <- read_xml("http://twiv.microbeworld.libsynpro.com/twiv") %>%
xml_nodes("item")
feed_items %>%
xml_nodes("pubDate") %>%
xml_text()
feed_items %>%
xml_nodes("itunes\\:duration") %>%
xml_text()
먼저 read_xml 함수로 해당 팟캐스트의 RSS 파일을 불러옵니다. RSS 파일은 전체 에피소드의 제목, 회차 ID, 음성 파일의 주소, 방송 길이, 키워드 등을 담고 있어요. 각 에피소드는 <item> 태그로 구분되고, 그 밑에 <title> (제목), <pubDate> (방송 일자) 등의 형식으로 내용을 담고 있습니다. 따라서, xml_nodes("item")은 팟캐스트 RSS 파일에서 각 회차의 자료를 담은 내용만을 남깁니다. 다음 xml_nodes("pubDate")를 적용하면 모든 회차의 방송 일자를, xml_nodes("itunes\\:duration")를 적용하면 모든 회차의 방송 길이를 불러오는 식입니다.
팟캐스트 RSS의 XML 양식은 모두 동일해요(물론 귀찮아서 그런 건지는 모르나 keyword는 없는 경우도 꽤 있긴 합니다). 필요한 내용을 추출하는 함수를 만들어볼게요.
feed_to_df <- function(rss) {
feed_items <- read_xml(rss) %>%
xml_nodes("item")
feed_df <- data_frame(pubDate = feed_items %>% xml_nodes("pubDate") %>% xml_text(),
title = feed_items %>% xml_nodes("title") %>% xml_text(),
encLength = feed_items %>% xml_nodes("enclosure") %>% xml_attr("length"),
duration = feed_items %>% xml_nodes("itunes\\:duration") %>% xml_text()) %>%
mutate(pubDate = dmy_hms(pubDate)) %>%
mutate(encLength = as.numeric(encLength),
duration = ifelse(grepl(":\\d+:", duration), duration, paste0("00:", duration)),
duration_seconds = as.numeric(hms(duration)))
feed_df
}
rss를 넣어주면 RSS에서 pubDate, title, enclosure (파일 크기), itunes\\:duration을 추출하여 data_frame을 통해 tibble 형식의 데이터 프레임을 만듭니다. 다음 pubDate에 적용한 dmy_hms() 함수는 “일 월 년 시:분:초”(예, 14 Oct 2017 12:40:36)를 R의 시간 자료형으로 변경해주는 함수입니다. 팟캐스트 RSS는 시간을 “Sat, 14 Oct 2017 12:40:36 +0000” 형식으로 담고 있는데, lubridate의 dmy_hms는 필요 없는 요일과 마지막의 표준 시간대 지정자를 제외한 시간 값을 추출해줍니다.
duration의 경우, 한 시간 안쪽으로 끝난 방승은 “30:00”, 한 시간이 넘어간 방송은 “1:10:00”의 형식으로 표현되어 있기 때문에 grepl(":\\d+:")로 한 시간 안쪽 방송시간 앞에 "00:"을 불여주었어요. 다음 초 형식으로 바꾸는 데는 다시 lubridate의 hms() 함수가 수고해 주었습니다.
정리된 RSS가 어떤 모습인지 한번 볼까요?
# 지대넓얕 RSS 주소입니다.
jdny_df <- feed_to_df("http://api.podty.me/api/v1/share/cast/390937d3e5c758aa6f4005b63542cc83695b4d5e6925fe6a2d4d488d1d05d748/146364")
jdny_df %>%
top_n(5, wt = pubDate) %>%
kable()
| pubDate | title | encLength | duration | duration_seconds |
|---|---|---|---|---|
| 2017-08-19 22:23:05 | 155회 - [결산] 안녕, 지대넓얕 | 43755908 | 01:11:12 | 4272 |
| 2017-07-29 22:27:49 | [공지] 지대넓얕 시즌 종료 안내 | 732390 | 00:01:12 | 72 |
| 2017-07-29 22:23:32 | 154회 - [예술] 십우도 (2부) | 24992675 | 00:39:55 | 2395 |
| 2017-07-29 22:22:14 | 154회 - [예술] 십우도 (1부) | 27987091 | 00:44:55 | 2695 |
| 2017-07-22 22:36:47 | 153회 - [예술] LIFE 그리고 사진 (2부) | 35932761 | 00:58:09 | 3489 |
먼저 방송의 scatter plot을 그린 뒤, LOESS로 회귀선을 그려볼 겁니다.
jdny_df %>%
mutate(duration_minutes = duration_seconds / 60) %>%
ggplot(aes(pubDate, duration_minutes)) +
geom_point() +
geom_smooth() +
labs(x = "날짜", y = "방송시간 (분)",
title = "지적 대화를 위한 넓고 얕은 지식") +
scale_x_datetime(date_breaks = "1 year", date_labels = "%Y")
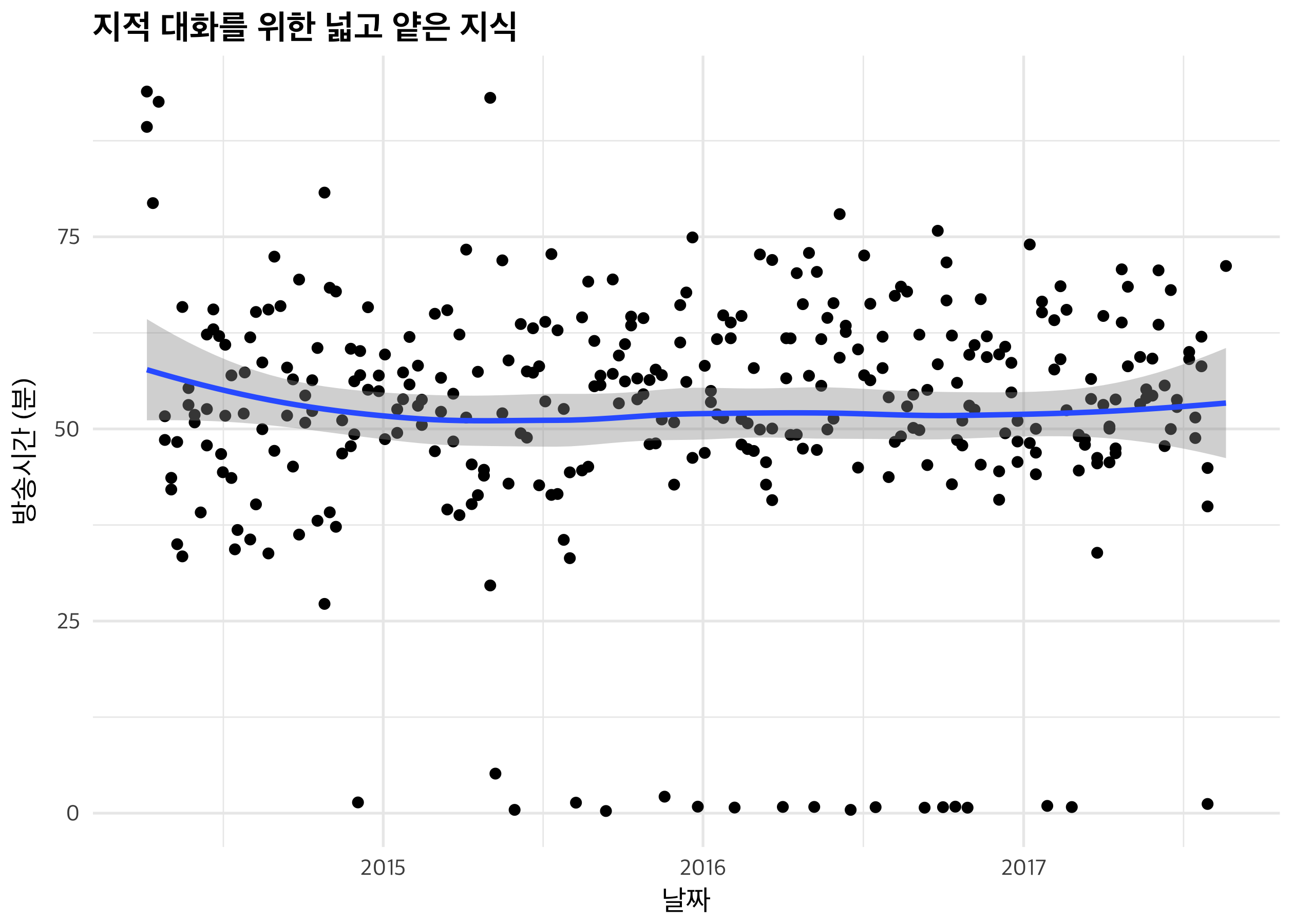
방송 시간은 평균 한 시간 안쪽으로 떨어지는 것 같습니다. 초반에는 한 시간 반에 가까운 outlier가 보이지만, 대부분 시간을 맞춰 편집하고 있는 것으로 보입니다. geom_smooth는 회귀 곡선을 추가해주는 함수, scale_x_datetime은 X축 값이 시간 형식일 때, 표현 방식을 결정해주는 함수예요. date_breaks = "1 year"로 1년마다 구분선을 그리도록 설정했습니다.
다음은 box plot입니다.
jdny_df %>%
mutate(duration_minutes = duration_seconds / 60,
Year = year(pubDate)) %>%
group_by(Year) %>%
summarise(mean_duration = mean(duration_minutes, na.rm = TRUE)) %>%
ggplot(aes(Year, mean_duration)) +
geom_col(fill = wes_palette("Royal1")) +
labs(x = "연도", y = "평균 방송시간 (분)",
title = "지적 대화를 위한 넓고 얕은 지식",
subtitle = "평균 방송시간") +
scale_x_continuous(breaks = 2014:2017)

summarise로 연도별 평균을 내었어요. geom_col의 wes_palette("Royal1")은 영화 The Royal Tenenbaums의 주 색조를 전달해줍니다. 방송 시간을 꾸준하게 유지하고 있는 것을 볼 수 있어요. 원 포스트의 출발점이 This Week in Virulogy 팟캐스트가 점점 길어지고 있는 것 갈다는 생각을 검증해보려고 했던 것이었고 저도 여러 팟캐스트를 들으면서 비슷한 생각을 했었던 것 같아 다른 팟캐스트들에 적용해본 것입니다만, 지대넓얕은 방송 시간 편집을 잘 하고 있는 것 같아요.
다음은 오늘의 핵심, density ridgeline plot입니다.
jdny_df %>%
mutate(duration_minutes = duration_seconds / 60,
Year = factor(year(pubDate), levels = 2017:2014)) %>%
filter(!is.na(duration_minutes)) %>%
ggplot(aes(x = duration_minutes, y = Year, fill = Year)) +
geom_density_ridges(scale = 4) +
scale_fill_cyclical(values = wes_palette("Moonrise1")) +
theme_jk_ridge() +
labs(x = "방송시간 (분)", y = "연도",
title = "지적 대화를 위한 넓고 얕은 지식",
subtitle = "연도별 방송시간 분포") +
scale_x_continuous(breaks = seq(0, 120, 30), limits = c(0, 120))
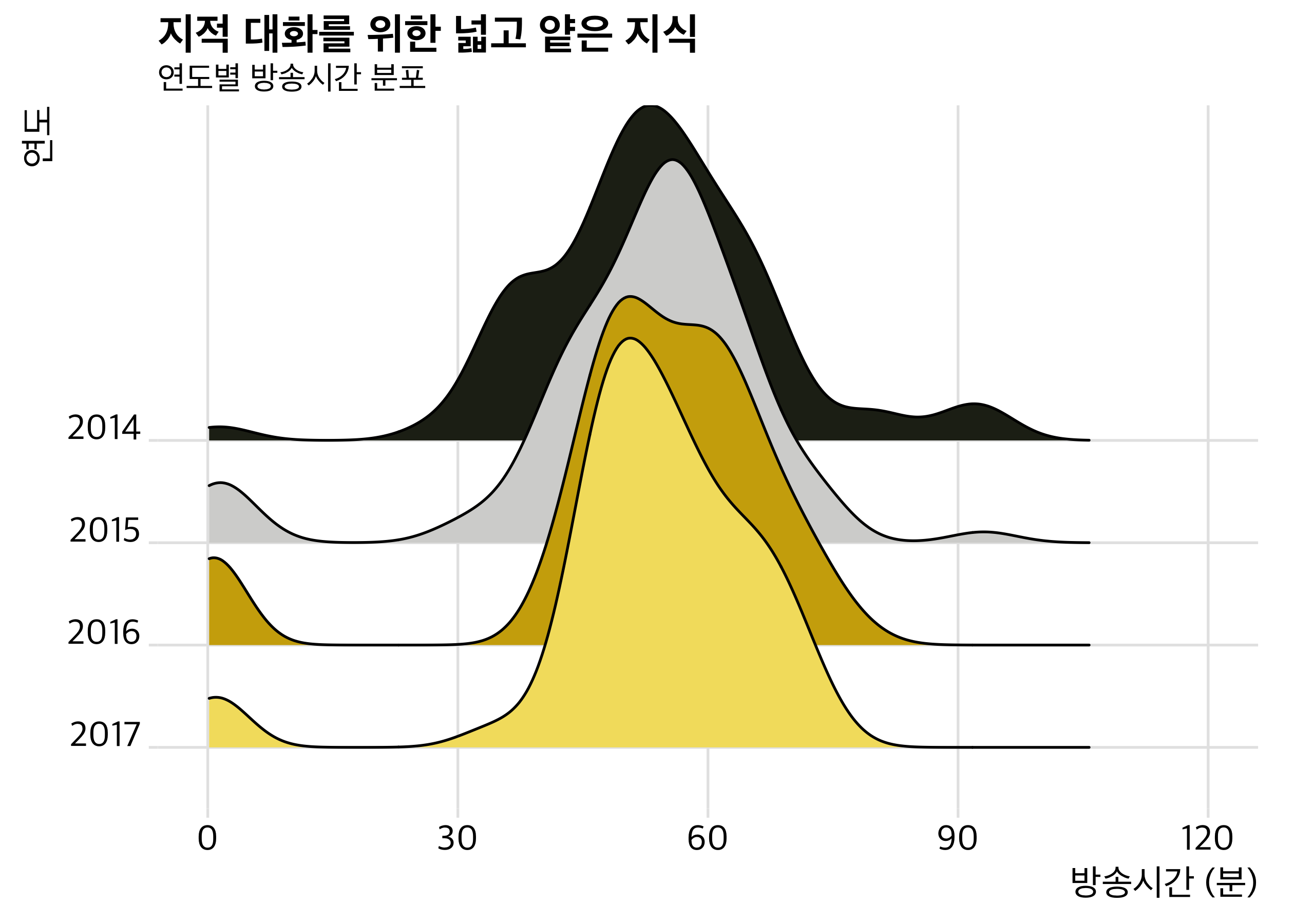
density ridgeline plot은 일련의 histogram을 겹쳐놓은 것입니다. 수평축(X축)은 동일하게 맞추고, 약간씩 겹쳐서 자료를 제시합니다. 마치 산등성이를 보는 것 같은 느낌을 줘서 ridgeline이라는 이름이 붙었고, 최근 동일 계열의 자료들을 비교 시각화하는 데에 있어서 인기를 끌고 있는 시각화 방법입니다. geom_density_ridges를 통해 시각화하며, ggplot(aes)에서 x에 자료값을, y에 grouping variable을 입력하여 그릴 수 있어요. 방송이 진행되면서 방송시간이 점차 50분에 맞춰져가는 모습이 잘 보이네요.
중간에 나오는 theme_jk_ridge()는 미리 정의해둔 theme_ridges()의 수정본입니다. 보통은 theme_ridges(fond_family = "Nanum Gothic") 정도면 충분할 것 같습니다.
다른 방송과 비교해 볼까요?
grs_df <- feed_to_df("http://www.xsfm.co.kr/xml/idwk.xml") # 그알싫 RSS
ms_df <- feed_to_df("http://www.phnara.com/gtv7/feed.xml") # 망치부인 RSS
jdny_df %>%
mutate(show = "지대넓얕") %>%
bind_rows(mutate(grs_df, show = "그알싫")) %>%
mutate(duration_minutes = duration_seconds / 60,
Year = factor(year(pubDate), levels = 2017:2014)) %>%
filter(!is.na(duration_minutes)) %>%
ggplot(aes(x = duration_minutes, y = Year)) +
geom_density_ridges(aes(fill = show), alpha = 0.4) +
theme_jk_ridge() +
theme(legend.title = element_blank()) +
labs(x = "방송시간 (분)", y = "연도",
title = "연도별 방송시간 분포") +
scale_x_continuous(breaks = seq(0, 300, 30)) +
scale_fill_manual(values = c("blue", "red"))

두 팟캐스트를 비교해 보았습니다. 그알싫의 특정 회차는 네 시간을 넘는 경우도 있네요. 전체적으로 봤을 때 그알싫은 90~120분을 유지하다가 2017년 들어 한 시간에 가까워지고 있는 반면, 지대넓얕은 상당히 일관된 방송시간을 보여주고 있는 것을 알 수 있습니다.
같은 그래프이지만, 두 개로 나눠서 다시 그려볼게요.
jdny_df %>%
mutate(show = "지대넓얕") %>%
bind_rows(mutate(grs_df, show = "그알싫")) %>%
mutate(duration_minutes = duration_seconds / 60,
Year = factor(year(pubDate), levels = 2017:2014),
show = factor(show, levels = c("지대넓얕", "그알싫"))) %>%
filter(!is.na(duration_minutes)) %>%
ggplot(aes(x = duration_minutes, y = Year, fill = show)) +
geom_density_ridges(scale = 4, alpha = 0.4) +
theme_jk_ridge() +
theme(legend.title = element_blank()) +
labs(x = "방송시간 (분)", y = "연도",
title = "연도별 방송시간 분포") +
scale_x_continuous(breaks = seq(0, 180, 60), limits = c(0, 180)) +
facet_wrap(~ show)
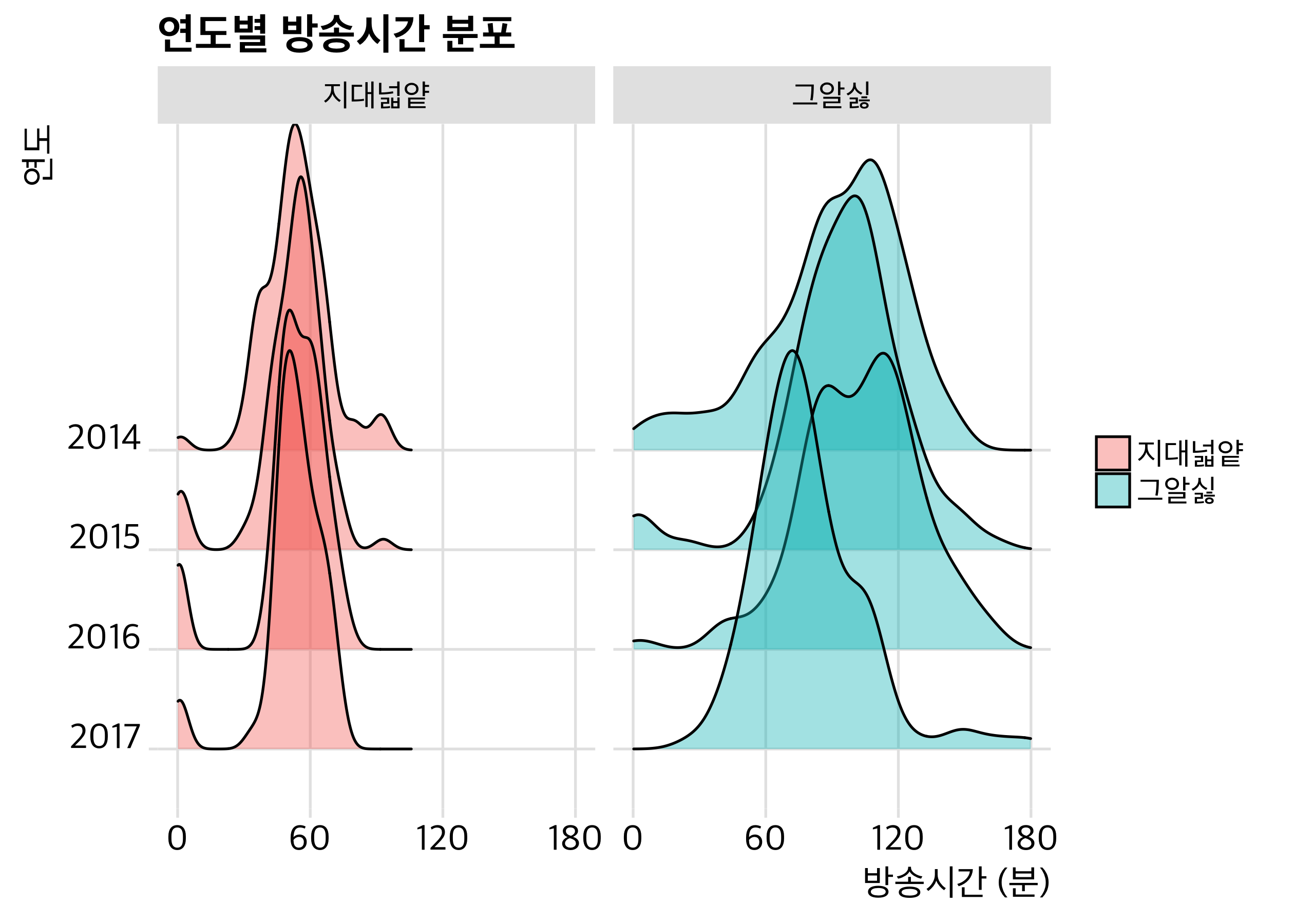
시각화를 위해 180분 이상은 그리지 않았습니다(scale_x_continuous(limits = c(0, 180))). 결과는 위 그래프와 동일하고요. 어느 쪽을 사용할지는 자료에 따라 다른 것 같아요. 이 경우엔 앞의 그래프가 더 보기 좋다는 생각이 듭니다. 한 화면에서 두 개의 그래프로 나눌 때에는 facet_wrap() 함수를 추가한다는 점을 기억해주세요.
마지막으로, 세 팟캐스트를 비교해보려고 합니다.
jdny_df %>%
mutate(show = "지대넓얕") %>%
bind_rows(mutate(grs_df, show = "그알싫")) %>%
bind_rows(mutate(ms_df, show = "망치부인")) %>%
mutate(duration_minutes = duration_seconds / 60,
Year = factor(year(pubDate), levels = 2017:2014),
show = factor(show, levels = c("지대넓얕", "그알싫", "망치부인"))) %>%
filter(!is.na(duration_minutes)) %>%
ggplot(aes(x = duration_minutes, y = show, fill = show)) +
geom_density_ridges(scale = 4) +
theme_jk_ridge() +
theme(legend.title = element_blank()) +
labs(x = "방송시간 (분)", y = "방송",
title = "방송별 방송시간 분포") +
scale_x_continuous(breaks = seq(0, 300, 60)) +
scale_fill_manual(values = wes_palette("GrandBudapest2", 3))
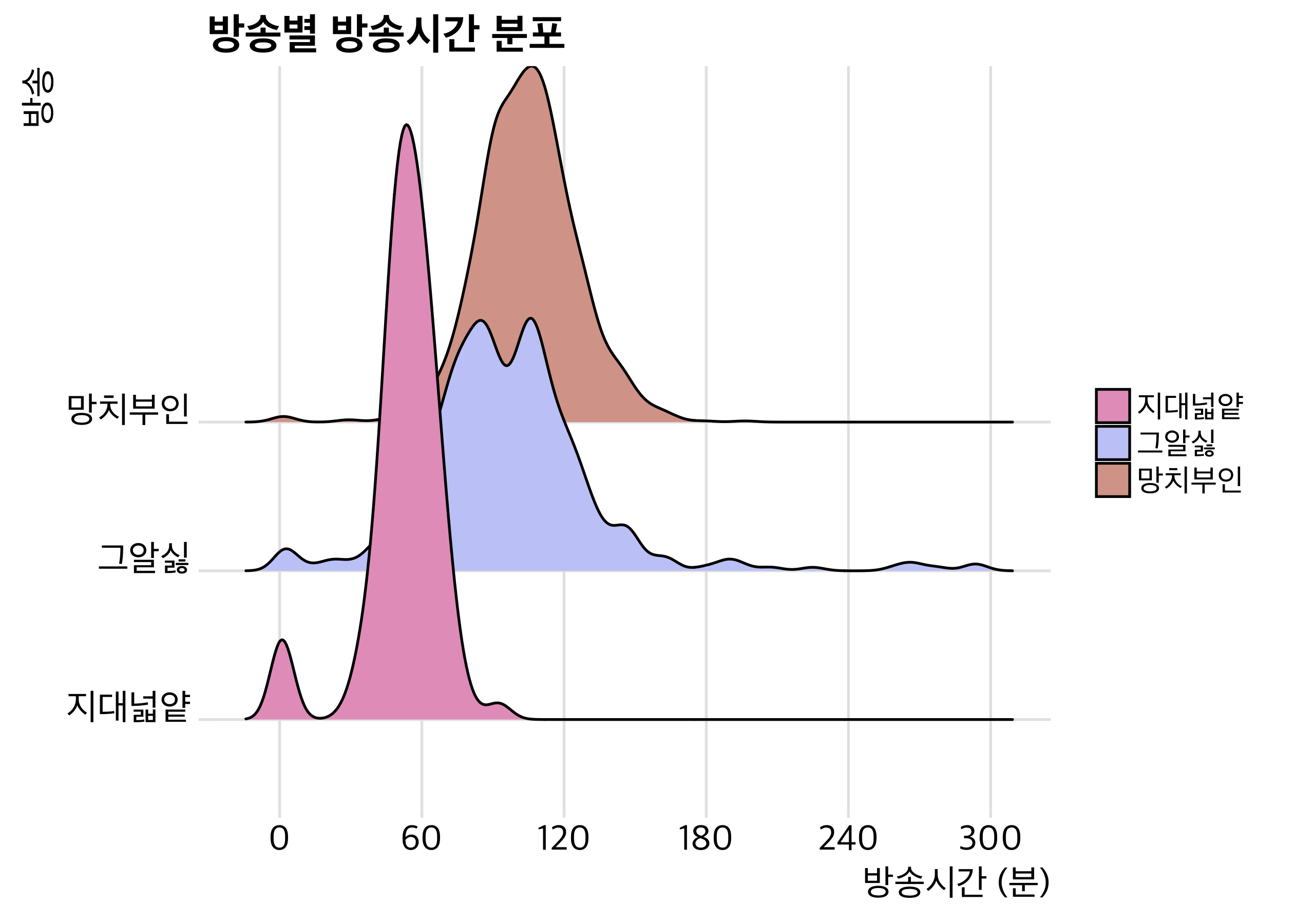
망치부인의 시사수다는 두 시간, 지대넓얕은 한 시간에 쏠려 있어요. 반면 그알싫은 방송마다 시간이 다양하게 나타나는 것을 볼 수 있네요. 망치부인의 시사수다가 아프리카TV에서 출발한 것이 원인 중 하나가 아닐까 생각해봅니다.
키워드 시각화
마지막으로 지대넓얕의 키워드를 wordcloud로 시각화해볼 겁니다. 다른 자료도 있으면 좋을 텐데, 키워드가 정리되어 있는 방송이 잘 없네요. 제목을 형태소 분석해서 써볼까도 생각했는데, 아무래도 문장이 아니다 보니 아쉬워서 추가하지는 않았습니다. 먼저 코드를 볼게요.
data_frame(keywords = read_xml("http://api.podty.me/api/v1/share/cast/390937d3e5c758aa6f4005b63542cc83695b4d5e6925fe6a2d4d488d1d05d748/146364") %>%
xml_nodes("item itunes\\:keywords") %>%
xml_text()) %>%
unnest_tokens(words, keywords) %>%
count(words) %>%
filter(!words %in% c("지적", "지적대화", "대화를"
, "위한", "넓고", "얕은", "지식", "지대넓얕", "jdny", "팟티", "채사장", "김도인", "깡선생", "독실이", "깡쌤", "이독실", "덕실이", "이덕실", "2")) %>%
with(wordcloud(words, n, scale = c(5, .3), min.freq = 8, random.order = FALSE, colors = wes_palette("Royal1"), family = "Apple SD Gothic Neo"))

앞서 정리하지 않았던 <keyword> 태그만을 추출했습니다(xml_nodes("item itunes\\:keywords") %>% xml_text()). 다음 tidytext를 사용해서 단어 숫자로 정리했어요. wordcloud 그리실 때 tm 패키지로 corpus -> tm -> findfreq를 많이 쓰실 텐데요, tidytext의 unnest_tokens와 count 함수를 쓰면 아주 간단하게 정리하실 수 있습니다. 한글 자료에서 형태소 분석한 뒤 tokenization 하는 부분은 제 패키지, RmecabKo 다음 판올림에 포함하려고 생각하고 있으니 기대해주세요.
너무 많이 언급된 단어들을 filter를 통해 제외한 후, wordcloud를 그립니다. 워드 클라우드 시각화의 핵심은 scale 값과 색깔 선택에 있다고 해도 과언이 아니에요. min.freq 값을 잘 정해서 잘 안 나타나는 단어들을 제외하는 것도 중요하지만, scale의 두 값을 잘 정해서 단어 크기의 범위를 잘 정해주는 것이 중요합니다. random.order = TRUE를 설정하면 최빈 단어가 중심에, 빈도가 적을수록 외곽에 위치하면서 원형으로 시각화가 되는 반면, random.order = FALSE로 잡으면 빈도와 상관없이 위치가 결정되면서 사각형에 가깝게 시각화가 되니 자료에 따라 적절히 활용하시면 좋아요.
의외로 제일 많이 다룬 것은 “역사”군요. “과학”과 “철학”이 그 뒤를 잇고 있고요. “영화”가 많이 다뤄졌다는 것도 생각지 못했던 부분인 것 같아요. “종교”, “영혼”, 여러 국가의 이름 등 어떤 주제들이 다뤄졌는지를 잘 보여주고 있다고 생각합니다. 이렇게 놓고 보니, 지대넓얕이 상당히 공평하게 분야를 다루고 있다는 인상이 정확한 것은 아니었네요. 덧불여, 4년 동안 방송을 진행해온 지대넓얕 패널 여러분께 이 자리를 빌려 감사를 표합니다.
마치며
오늘은 자료 분석 기법보다는 시각화 방법을 소개하는 데 초점을 맞춘 것 같아요. XML 파일 분석에는 동일한 방법을 적용할 수 있다는 점, (혹시라도 팟빵 정책이 변경된다던지 해서 다른 팟캐스트 RSS 파일을 구할 수 있다면) 팟캐스트의 변천과 주제를 분석할 수 있다는 점이 이번 포스트의 주안점이 아니었나 자평해 봅니다. 더 재미있는 자료로 찾아뵙겠습니다.
Comments