네이버 블로그로 동시출현단어 분석 (co-occurence network anlysis)
동시출현(Co-occurrence)이란 한 문장, 문단 또는 텍스트 단위에서 같이 출현한 단어를 가리킵니다. 언어학적 의미에서 의미적 근접성을 가리키며, 단어의 연결(collocation)을 찾는 데 활용됩니다. 이 개념에서 출발한 동시출현 네트워크(Co-occurrence networks)는 특정 텍스트 단위에서 공동으로 출현한 단어의 집합적 상호 연결을 표현하는 방식입니다. 나타나는 단어를 모두 표시한 뒤, 두 단어가 같은 문단에 들어가 있다면 둘 사이를 선으로 연결해 나가다 보면 단어의 네트워크를 만들 수 있게 되겠죠. 이번 포스트에서는 네이버 블로그를 검색하여, 동시출현 네트워크를 그려보는 것을 목표로 합니다. 시각화에는 두 개의 패키지, qgraph와 networkD3를 활용해볼 것입니다. 일반적으로 사용되는 igraph가 군집 분석이 가능한 장점을 지니지만, 이번에는 단순히 시각화를 목적했습니다.
들어가기 전에
본 포스트는 다음 블로그를 참조하여 작성하였습니다.
- kdy0573님의 블로그: 네이버 블로그 빈도 분석 (아이스크린)
- Data and Visualization: NetworkD3 (이민호)
- From future Import Dream: 텍스트 마이닝을 통한 SNA (전희원)
사용 package
계속 말씀드린대로 이번에는 전희원 님의 KoNLP를 사용했습니다. NIA dictionary를 활용합니다.
library(rvest)
library(KoNLP)
library(stringr)
library(tm)
library(qgraph)
library(dplyr)
library(networkD3)
useNIADic()
크로울러
이번에도 rvest로 진행합니다. 코드가 상당히 간단한데, 네이버 대문에서 블로그를 검색하면 블로그 포스트의 첫 세 줄 정도를 제목, 이미지와 함께 보여주는 페이지를 긁어오는 방식입니다. 중간의 css='.sh_blog_passage'가 블로그 본문을 간단히 제시하는 부분을 추출하는 부분이 되겠습니다. 각 블로그를 다 들어가서 원문을 다 가져와야 하는 거 아니냐, 라고 물어보실 만도 한데, 동시출현 네트워크의 구성 상 각 텍스트가 긴 것 보다는 텍스트의 수가 많은 것이 좋습니다. 예컨대 트윗을 분석하거나, 논문의 제목 또는 초록을 분석하는 데에 쓸만합니다. 그 이유는, 텍스트가 길면 동시에 출현하는 단어도 너무 많아지기 때문에, 연관성을 확인하기 어려워지기 때문입니다. 이번에는 “텍스트 분석”을 검색어로 사용했어요.
따라서 네이버 블로그 검색 창에서 10개씩 넘기면서, 제목 하단의 짧은 텍스트를 받아와 searching 벡터에 모으는 방식으로 작업했습니다. 윈도우에서 작업하실 때엔 인코딩 변경에 주의해주세요.
keyword <- "텍스트+분석"
url <- paste0("https://search.naver.com/search.naver?where=post&sm=tab_pge&query=", keyword, "&st=sim&date_option=0&date_from=&date_to=&dup_remove=1&post_blogurl=&post_blogurl_without=&srchby=all&nso=&ie=utf8&start=")
searching <- c()
for(page in seq(1, 1000, by=10)) {
page_url <- paste0(url, page)
result <- read_html(page_url) %>%
html_nodes(css='.sh_blog_passage') %>%
html_text()
# result <- iconv(result, "UTF-8", "CP949") # 윈도우의 경우, R 작업환경에 맞춰 CP949로 변경할 필요가 있습니다.
searching <- c(searching, result)
Sys.sleep(runif(1, 0, 1))
}
Tokenizing
이어 텍스트에서 원하는 형태소를 추출합니다. 이번에는 KoNLP의 SimplePos22 함수를 이용하여 tagging한 후, 그 중 형태소 분류가 N, P로 시작하는 것만을 수집하였습니다. 한 글자인 경우(대명사 등)는 단어 네트워크에서는 해석이 모호하기 때문에 한꺼번에 제외시킬 것입니다. 형태소를 골라내는 ko_words 함수를 만들고, 수집한 텍스트에서 기호 등을 제거한 뒤 Map 함수로 전체에 적용했습니다.
| N: 체언 | P: 용언 |
|---|---|
| NC: 보통명사 | PV: 동사 |
| NQ: 고유명사 | PA: 형용사 |
| NB: 의존명사 | PX: 보조용언 |
| NP: 대명사 | |
| NN: 수사 |
참고: KAIST 품사 태그셋 중 N, P 태그셋
ko_words <- function(doc) {
d <- as.character(doc)
pos <- unlist(SimplePos22(d))
extracted <- str_match(pos, '([가-힣]+)/[NP][A-Z]')
keyword <- extracted[, 2]
keyword[!is.na(keyword)]
}
texts <- searching %>%
str_replace_all(pattern="\r", replacement="") %>%
str_replace_all(pattern="\n", replacement=" ") %>%
str_replace_all(pattern="[[:punct:]]", replacement=" ") %>%
str_replace_all(pattern="[ㄱ-ㅎㅏ-ㅣ]+", replacement="") %>%
str_replace_all(pattern="/", replacement=" ") %>%
str_trim(side="both")
texts <- texts[texts != ""]
pos <- Map(ko_words, texts)
동시출현 매트릭스 생성
tm package를 통해 Term-Document Matrix를 만듭니다. Term-Document Matrix는 각 단어가 행을, 각 텍스트가 열을 이루는 구조를 지닙니다(transpose하면 Document-Term Matrix가 되지요). 이를 만들기 위한 함수 TermDocumentMatrix에서 wordLengths를 4 이상, 10 이하로 잡으면 한글은 하나에 두 글자로 취급하기 때문에 두 글자 이상 다섯 글자 이하의 단어만을 선정하게 됩니다. 동시출현 매트릭스를 생성하는 데에 있어서 또 중요한 parameter 중 하나가 weighting=weightBin인데요, 이 경우 해당 단어가 텍스트에 출현하면 1, 아니면 0을 반환합니다. weightTf는 출현하는 갯수만큼 표시하기 때문에, 동시출현 매트릭스를 만들 때 값이 너무 커지게 됩니다.
단어가 행에 배치되어 있으니, rowSums를 구하면 각 단어가 몇 개의 텍스트에 나타나는 지 구할 수 있습니다. 이걸 order(word.count, decreasing=TRUE)로 정렬해서, 빈도가 가장 높은 단어 30개만 추려낸 매트릭스를 만들었어요. 다음, 원 매트릭스와 역 매트릭스를 곱하면, row * column의 형태가 될 테니 나오는 매트릭스는 단어끼리의 빈도를 나타내는 매트릭스가 되겠네요.
stopWord(불용어)로 ‘텍스트’, ‘분석’을 넣었습니다. 검색어기 때문에 모든 텍스트에서 나타나서, 한가운데 짠, 하고 나타나기 때문에 그림을 보기가 더 불편해지거든요.
corpus <- Corpus(VectorSource(pos))
stopWord <- c("텍스트", "분석")
tdm <- TermDocumentMatrix(corpus, control=list(
removePunctuation=TRUE, stopwords=stopWord,
removeNumbers=TRUE, wordLengths=c(4, 10), weighting=weightBin))
tdm.matrix <- as.matrix(tdm)
word.count <- rowSums(tdm.matrix)
word.order <- order(word.count, decreasing=TRUE)
freq.words <- tdm.matrix[word.order[1:30], ]
co.matrix <- freq.words %*% t(freq.words)
시각화 1. qgraph
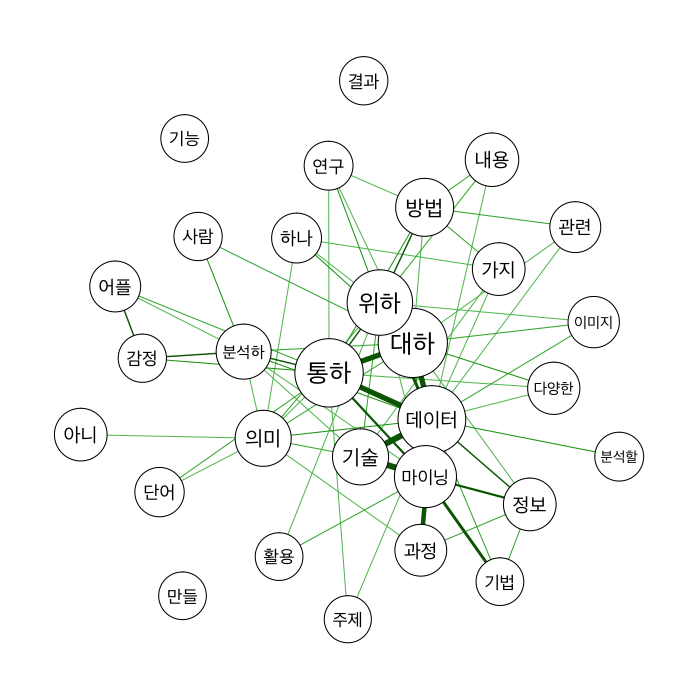
먼저 qgraph로 그려볼게요. qgraph는 별도로 폰트 설정 parameter가 없어서, par에 먼저 넣어줍니다. 저도 아직 해당 package에 관한 이해가 부족해서, 좀 더 살펴보아야 할 것 같아요. threshold로 작은 연결은 날려주고, 중요한 것만 놓아두었습니다.
‘대하다, ‘통하다’가 중간에 있네요. “(텍스트 분석)을 통해 ~에 대해 분석”한다는 표현이 아무래도 가장 많이 등장할 테니까요. ‘데이터’, ‘마이닝’이 아래에 보이고, ‘기술’, ‘정보’, ‘과정’ 등이 연결되어 있습니다. 반대쪽에는 ‘연구’, ‘방법’이 있네요. 왼쪽에는 ‘의미’, ‘분석’, ‘감정’ 등이 보여요. 텍스트 분석은 데이터 마이닝 연구 방법으로 소개되고 있다는 걸 확인할 수 있겠습니다. 주로 의미와 감정 분석에 활용되고 있는 것 같네요.
par(family="Apple SD Gothic Neo")
qgraph(co.matrix, labels=rownames(co.matrix),
diag=FALSE, layout='spring', threshold=3,
vsize=log(diag(co.matrix)) * 2)
시각화 2. networkD3
좀 더 다양한 시각화를 위해 networkD3 package를 살펴볼게요. 이건 D3.js로 그래프를 만들어 줍니다. 인터넷에서 interactive visualization이 가능한 장점이 있고, 쉽게 (igraph에 비해) 시각화를 할 수 있다는 장점이 있습니다.
먼저 원자료를 조금 변경해야 합니다. 두 개의 data frame, nodes와 links를 만들어야 해요. nodes에는 node 명과 index, node의 weight를, links에는 node 끼리의 연결을 표시해 줘야 합니다. 먼저 node_df는 동시출현 매트릭스에서 이름을 따오고, 행렬의 대각 값을 취해(diag(co.matrix)) 값으로 사용하도록 넣어줍니다. index가 0부터 시작해야 해서, mutate로 1씩 빼줬어요.
다음은 link_df를 left_join으로 만들었어요. as.data.frame(as.table(co.matrix))로 동시출현 매트릭스를 long form으로 만들 수 있습니다. 너무 연결이 많으면 시각화에 방해가 되기 때문에 적당히 잘라주고 (여기에서는 동시출현 4회 이상으로 잡았어요. 시도해봐서 적절한 값을 찾아줄 필요가 있습니다.) 여기에 node_df의 index 값을 붙인 link data frame을 만들었습니다.
node_df <- data_frame(node=rownames(co.matrix), value=as.numeric(diag(co.matrix))) %>%
mutate(idx=row_number()-1)
link_df <- as_data_frame(as.table(co.matrix)) %>%
filter(n > 4) %>%
rename(source=`Terms`, target=`Terms.1`) %>%
left_join(node_df %>% rename(source_idx=idx) %>% select(-value), by=c('source'='node')) %>%
left_join(node_df %>% rename(target_idx=idx) %>% select(-value), by=c('target'='node'))
결과를 간단하게 표시해 보면, 이렇게 나옵니다. 커서를 node 위에 올리면 살짝 확대되면서 텍스트를 확인할 수 있고, 이래저래 위치를 조정할 수 있습니다.
forceNetwork(Links=as.data.frame(link_df), Nodes=as.data.frame(node_df),
Source='source_idx', Target='target_idx',
NodeID='node', Group='node')

여러 parameter를 추가해 보았습니다. radiusCalculation은 node의 크기를 정하는 함수 또는 값인데, 자바스크립트 함수로 넣어주어야 합니다. 제곱근한 값에 3을 곱하는 것으로 설정했고요. linkDistance는 서로 간의 거리입니다. Nodesize, Value로 node 크기와 edge 크기도 정할 수 있어요.
결과는 qgraph로 그린 것과 비슷하지만, 상호작용이 가능한 그래프를 만들 수 있다는 장점이 있습니다.
forceNetwork(Links=as.data.frame(link_df), Nodes=as.data.frame(node_df),
Source='source_idx', Target='target_idx',
NodeID='node', Group='node', Nodesize='value', Value='n',
radiusCalculation=JS("Math.sqrt(d.nodesize) * 3"),
opacityNoHover=TRUE, linkDistance=100,
zoom=TRUE, opacity=0.8, fontSize=15,
fontFamily="Apple SD Gothic Neo")

마치며
이번에는 동시출현 매트릭스 형성, 그리고 간단하게 시각화하는 방법을 확인해 보았습니다. 요새 신문기사 등에 자주 등장하는 방법이고 연구조사방법론에서도 어느 정도 자리를 잡고 있는 것 같아요. 연구에 활용하려면 군집 분석 등을 추가하면 여러 각도에서 분석이 가능합니다. 다음 번에 좀 더 자세히 살펴볼게요.
Comments