환자 불편 사항 상담 자료 Word Vector로 분석해보기 (Semantic Analysis)
이번에는 한국 소비자상담센터의 상담 자료를 Word Vector로 분석해 보려고 합니다. 지난 번 글에서 말씀드린 작업 중에서, 감정 사전 번역 후 하나씩 형태소 사전과 매칭하는 작업을 진행 중입니다만 생각보다 손이 많이 가네요. 일단 다른 작업부터 하나 해 보았습니다. 소비자상담센터 - 상담조회 - 상담현황조회에는 서비스 불편 사항에 관한 여러 가지 상담 내용과 응답이 올라와 있습니다. 그 중에는 의료서비스도 있고요. 2010년부터 지금까지 상담한 내용이 올라와 있고, 질의와 응답이 모두 올라와 있어요. 모범 상담 조회에는 만족도도 표시되어 있으니 supervised learning도 해볼 수 있을 것 같고요. 오늘은 일단, 질문만 모두 모아서 word vector로 바꾸고, 어떤 작업들이 가능한지만 살펴볼 것입니다. 제가 이 자료에서 찾아보려는 것은 의과와는 구분되는 치과의 특성인데, 문제에 맞는 좋은 자료라고 생각합니다. 이 결과는 다음번에 소개드리겠습니다.
Word Vector
단어의 의미란 무엇인가,라고 할 때 답하기가 막막하죠. 언어학에서도 촘스키 계열의 생성 의미론과 레이코프 계열의 인지 의미론이 계속 대립 중인 것으로 알고 있고(단견이니 정확한 내용 알려주시면 감사하겠습니다), 철학 쪽에도 영미 철학의 크립키의 고정 지시자, 프랑스 철학의 데리다의 차연 개념이 서로 양립하기 어려운 선을 긋고 있는 것 같습니다. 일단 어려운 이야기는 넘어가고, 컴퓨터에서 어떻게 언어의 의미를 표현할 것인가에 관해 고민해 볼까요.
크게 두 가지 방법이 있습니다.
- 그냥 단어로 표현한다.
- 다른 값으로 대체한다.
1의 대표적인 예가 지난번 글에서 소개해드린 bag-of-words 모형입니다. 텍스트 안에 특정 단어가 몇 개 나오는지 세는 방식으로 텍스트를 표현하는 방식이죠. 문제는 세상에 단어가 너무 많아서, 텍스트를 숫자로 표현하면 0이 넘실대는 거대한 수열이 만들어지고, 저장과 계산이 힘들어진다는 것입니다. 저장할 내용에 “이 단어가 없다”는 내용이 추가되니까요. 전에 말씀드린 것처럼, 단어의 순서는 고려하지 않게 된다는 문제도 있습니다.
2의 방식을 생각해볼까요. 먼저, 단어의 의미를 구성하는 하부 집합을 만들어 표시하는 방법이 있을 것 같습니다. 예를 들어, “왕”이 무엇인지 표시하기 위해, `{“남자”, “통치”, “국가”, …} 등의 단어 집합을 정하는 것입니다. 좋은 방법이긴 한데, 이 집합을 설정하기가 어렵습니다. 어디서 끊어야 할지도 애매하고, 서로 외연이 맞지 않는 단어의 연쇄를 늘어놓는 게 좋은 표현이라는 보장도 없죠.
여기에 단어를 벡터로 표현하는 방식이 끼어듭니다. 단어가 어떤 “의미 공간” 안에 있고, 여러 의미 벡터의 결합으로 이뤄진다는 생각입니다. “왕”이라면, [남자: 0.99, 지배: 0.99, …], “여왕”이라면, [남자: 0.01, 지배: 0.99, …] 이런 식으로 나타내는 것 말입니다. 이렇게 표현하면, 단어의 계산이 가능해집니다. 예를 들어, 왕 - 여왕 = 남자 와 같은 계산이 가능해지는 것입니다.
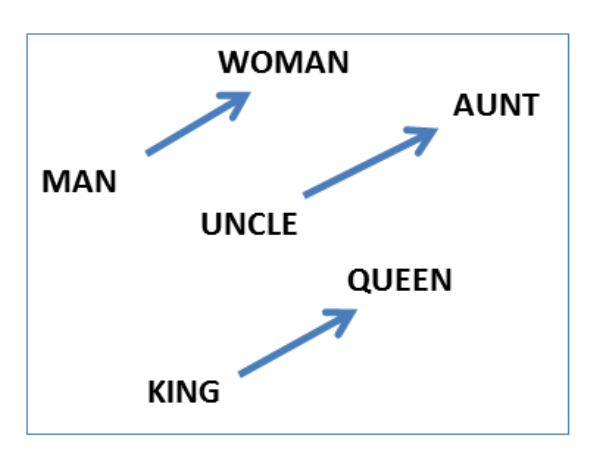
단어 벡터를 계산하기 위해서 도입한 방식이 c-bow와 skip-gram인데요, 다음번에 설명해야 할 것 같습니다. 간단하게는 한 단어의 앞뒤에 위치한 단어들을 통해 단어의 벡터 값을 계산하는 방식이라고 생각하시면 됩니다. 같은 위치에 들어가는 단어는 비슷한 의미를 지닌다고 생각할 수 있으니까요. “철수는 밥을 먹는다”와 “철수는 빵을 먹는다” 두 텍스트가 있다면, “밥”과 “빵”은 비슷한 의미를 지니고 있을 겁니다.
서론이 길었네요. 분석으로 넘어갈게요.
라이브러리
이번에는 wordVectors, tsne, ggdendro가 추가되었습니다. wordVectors package가 이번 분석의 핵심이 될 것 같고, 나머지는 시각화를 위한 패키지입니다.
library(rvest)
library(stringi)
library(tidyverse)
library(tidytext)
library(rJava)
library(wordVectors)
library(tsne)
library(ggplot2)
library(ggdendro)
크로울러
먼저 소비자상담센터의 텍스트를 긁어와야 합니다. Scrapy로 하면 빠르겠지만, 고작 1800개 긁어오기에는 과한 감도 있는 것 같고, R로 해보자 하는 마음에 그냥 rvest로 진행했습니다.
base_url_prefix <- "http://www.1372.go.kr/contents/include.ccn?gSiteCode=2&gMenuCode=4&nMenuCode=13&mPart=&startCount="
base_url_suffix <- "0&impbcd=380000"
article_list <- c()
먼저 텍스트의 링크를 모아옵니다. 서버가 내부 스크립트를 돌려 결과물을 만들어 출력해주는 방식이라, 검색이 좀 귀찮습니다. 따라서, 의료서비스 항목에 올라와 있는 글 전체의 목록을 만든 뒤, 각각을 긁어오는 방식으로 작업했습니다. R-like way of coding이라고 할까요.
for(i in 1:177) {
temp <- read_html(paste0(base_url_prefix, i, base_url_suffix))
new_article <- temp %>%
html_nodes(xpath='//table[@class="boardList"]/tbody/tr/td[@class="subject"]/a/@href') %>%
html_text()
article_list <- c(article_list, new_article)
}
article_list에 의료 주제 관련 글 링크를 모두 수집했습니다. 이제 세부적으로 내용을 모아볼게요.
# Getting items
base_url ="http://www.1372.go.kr"
pb <- txtProgressBar(min=0, max=length(article_list), style=3)
articles <- data_frame(title=character(), id=character(), rec=character(), cat=character(), main=character(), man=character(), ans=character())
for(i in 1:length(article_list)) {
temp <- read_html(paste0(base_url, article_list[i]))
temp_t <- temp %>%
html_nodes(xpath='//th[@id="contentsViewTitle"]') %>%
html_text()
temp_b <- temp %>%
html_nodes(xpath='//table[@class="boardView mgT10"]/tbody/tr/td') %>%
html_text()
setTxtProgressBar(pb, i)
temp_d <- data_frame(title=temp_t, id=temp_b[1], rec=temp_b[2], cat=temp_b[3], main=temp_b[4], man=temp_b[5], ans=temp_b[6])
articles <- bind_rows(articles, temp_d)
}
각 글을 열어서 제목, 식별자, 등록일자, 분류, 상담 내용, 답변일자, 답변을 저장합니다. 사이트가 느려서 진행 바를 추가했습니다. 생각보다 모아오는 데 오래 걸려서 후회했습니다. 수집 결과를 볼까요?
as_tibble(articles)
## # A tibble: 1,758 × 7
## title
## <chr>
## 1 피부과 패키지 결제후,병원 원장이 잠적 및 무단 폐업하였습니다.
## 2 자동차보험에 의한 치료에 대한 안내 불성실
## 3 바가지 쓴 금액 다시 돌려받고 싶습니다.
## 4 이빨 뽑은 후 금이 돌려 주지 않음
## 5 2011년 #####회사의 제대혈을 계약했습니다.
## 6 ###한의원 매선침 치료 불만 신고
## 7 사건2017-##### 답변의답변
## 8 한의원에서 다이어트 상담비로 3만원을 요구합니다.
## 9 오진
## 10 진료비 부당청구
## # ... with 1,748 more rows, and 6 more variables: id <chr>, rec <chr>,
## # cat <chr>, main <chr>, man <chr>, ans <chr>
(식별 가능성이 있는 단어는 삭제했습니다.)
자료 구축
모은 자료 중 상담 내용만 뽑아서, 전처리를 합니다. 치과 중심으로 분석할 예정이기 때문에, “인플란트, 임플런트, 임플랜트” 등을 “임플란트”로, “스켈링, 스캘링” 등을 “스케일링”으로 바꾸는 작업을 먼저 진행했습니다. 다음, 시간, 개수 등에 관해 토큰 처리를 하고 나머지 숫자와 “ㅋㅋ”, “ㅜㅜ” 등 한글 이용한 이모티콘은 삭제했습니다. 이것도 다음번엔 토큰 처리하면 더 좋겠네요.
# Building test data: Using morpheme extractor
question <- as.character(unique(articles$main))
question <- stri_replace_all_regex(stri_trans_nfkc(question), "[[:punct:]]", "") %>%
stri_replace_all_regex("[임|인]플[란|런|랜]트", "임플란트") %>%
stri_replace_all_regex("스[켈|케일|캘]링", "스케일링") %>%
stri_replace_all_regex("레진(치료)*", "레진") %>%
stri_replace_all_regex("[0-9]+개월", "<DUR> ") %>%
stri_replace_all_regex("[월|화|수|목|금|토|일]+요일", "<WK> ") %>%
stri_replace_all_regex("[0-9]+년", "<YR> ") %>%
stri_replace_all_regex("[0-9]+월", "<MON> ") %>%
stri_replace_all_regex("[0-9]+일", "<DAY> ") %>%
stri_replace_all_regex("[아침|오전|점심|저녁]*[0-9]+시", "<HR> ") %>%
stri_replace_all_regex("[0-9]+분", "<MIN> ") %>%
stri_replace_all_regex("[0-9]+원", "<PAY> ") %>%
stri_replace_all_regex("[0-9]+개", "<NUM> ") %>%
stri_replace_all_regex("[0-9]+(회|번)", "<TIM> ") %>%
stri_replace_all_regex("[0-9]+", "") %>%
stri_replace_all_regex("\\s+", " ") %>%
stri_replace_all_regex("http[a-zA-Z0-9]+", "") %>%
stri_replace_all_regex("[ㄱ-ㅎㅏ-ㅣ]+", "<UNK> ")
이번에도 코모란을 사용했습니다. 지난번처럼 명사만 추출하지 않고, 형태소 모두를 태그까지 받아와서 정리한 다음, 다빈도의 의미 없는 표현들(조사나 어미 등)을 불용어로 처리해 제외시켰습니다. 분석 중간에 깨달았는데 형태소 분석기가 “레진”을 처리 못해서 “레지”, “레”, “진”으로 나눠놓았네요. 다음번엔 사용자 사전에 “레진”을 추가해서 진행하면 더 좋을 것 같습니다.
# tokenization, remove tokens with 1 occurrence
questions <- data_frame(text=question)
questions$tag <- sapply(questions$text, function(x) { get_token_komoran(x) })
questions$concat <- sapply(questions$tag, function(x) { paste0(as.character(unlist(x)), collapse=" ") })
texts <- data_frame(text=questions$concat)
tokens <- texts %>%
unnest_tokens(word, text, token=stringr::str_split, pattern=" ", drop=FALSE) %>%
rownames_to_column()
word_count <- tokens %>%
count(word) %>%
arrange(desc(n))
# 불용어 처리: 1회만 나타난 단어 또는 다빈도 130 순위까지에서 중요 단어 제외하여 선정
stop_words <- word_count[, 1]
# stop_words <- bind_rows(stop_words, word_count[1:130, 1]) # 실제로는 10개 정도씩 확인해가면서 필요없는 단어를 불용어 목록에 포함시켰습니다.
stop_words <- bind_rows(stop_words, filter(word_count, n == 1)[, 1])
token <- anti_join(tokens, stop_words, by="word")
token <- arrange(token, as.numeric(rowname))
tidy_question <- token %>%
group_by(text) %>%
mutate(tidy_text = paste0(word, collapse=" "))
tidy_questions <- as.character(unique(tidy_question$tidy_text)) %>%
stri_replace_all_regex("\\+[a-z]+", "")
토큰으로 만들어 불용어 제외 후, 결합하여 태그 삭제한 상태입니다.
tidy_questions[1]
## [1] "day pay 결제 tim 시술 중 tim 진행 완료 day pay 결제 tim 시술 중 tim 진행 완료 day pay 결제 tim 시술 중 tim 진행 완료 이렇 결제 완료 및 시술 받 아무 문제 없이 평소 처럼 mon day 원래 예약 되 병원 방문 mon day 까 휴지 ㄴ다는 문 앞 붙 안내 보 귀가 이후 day 월 자 다시 예약 잡 으려 전화 고객 사정 의하 당분간 수신 정지 라며 전화 안 되 원장 핸드폰 안받 문자 카 톡 및 연락 전혀 안 되 상황 답답 보건소 연락 보 결과 해당 원장 이미 폐업 신고 다른 곳 이전 준비 답변 듣 현재 아무런 보상 및 연락 취하 않 상황 이 따라 결제 금액 중 못 받 시술 금액 보상 받 싶 으며 이러 문제 해결 위하 정신 적 스트레스 물리 적 시간 및 비용 전부 보상 받 고자 위자료 청구 고자 혹시나 상세 정보 남기 병원 홈페이지 주소 경기도 ##시 tim 길 층 ~ 호 사업자 등록 번호 대표자 민"
Word Vector
Schmidt의 wordVectors package는 Jian Li의 word2vec code를 이용해서 VectorSpace model을 구축합니다. 모형 구축을 위해서는 텍스트 파일 저장 후, train_word2vec 함수를 통해 모형을 구축하는 과정을 거칩니다. 몇 개의 벡터로 구성할지(vectors), 앞 뒤 몇 개의 단어를 볼 건지(window) 등이 중요한데요, 텍스트 자료의 model tuning은 지표가 없어서 정답이 있다고 보긴 어렵습니다.
writeLines(tidy_questions, '1372_question_tag.txt')
# Best model을 위한 hyperparameter tuning을 좀 더 고민해봐야 할 것 같습니다.
w2v_model <- train_word2vec('1372_question_tag.txt', '1372_question_vectors_tag.bin',
vectors=200, threads=4, window=10, iter=10, negative_samples=4, force=TRUE)
# 다음 번에 다시 불러오려면
# w2v_model <- read.vectors('1372_question_vectors_tag.bin')
이제 모형 구축이 완료되었습니다. 간략하게 살펴볼까요?
유사성 검색
유사 단어 검색부터 해보는 게 좋겠네요.
w2v_model %>% closest_to('임플란트')
## word similarity to "임플란트"
## 1 임플란트 1.0000000
## 2 fixture 0.6211481
## 3 흔들리 0.5403144
## 4 인공뼈 0.5392696
## 5 치과 0.5282731
## 6 브릿지로 0.5242733
## 7 치조골 0.5146833
## 8 나사 0.5098913
## 9 보철 0.5040480
## 10 발치 0.4957664
“임플란트”의 경우 “fixture”, “흔들리”, “인공뼈”, “브릿지로” 등등의 단어가 유사 단어로 검색됩니다. 상담 자료라는 걸 생각해 볼 때, 임플란트와 관련해 문제가 되는 것들이 주로 이 쪽이 아닐까 의심해볼만 합니다. 예컨대, 임플란트 관련 불편사항 중 가장 큰 것이 임플란트가 흔들리는 것이며, 시술 관련해서는 인공뼈 식립이나 임플란트 브릿지가 문제가 되는 경우가 많다고 생각해볼 수 있겠네요.
w2v_model %>% closest_to('교정')
## word similarity to "교정"
## 1 교정 1.0000000
## 2 장치 0.5307484
## 3 고르 0.5018805
## 4 덧니 0.4942421
## 5 frc 0.4906184
## 6 가지런 0.4832633
## 7 기울 0.4720108
## 8 교 0.4685329
## 9 교합 0.4556907
## 10 정비 0.4548219
“교정”의 경우는 “장치”, “고르” ,”덧니”, “frc(fiber-reinforced composite의 줄임말인 FRC는 FRC를 전치에 붙이고 미니스크류 식립해 전치부만 급속교정하는 방식을 의미합니다)”, “가지런”, “기울”, “교합” 등이 보이네요. 치료 방식 중에서는 FRC 교정에 관한 상담이 많았던 것 같고, 교정 후 고르지 못하거나 기울어진 것 등이 문제가 되었던 것으로 보입니다.
w2v_model %>% closest_to('스케일링')
## word similarity to "스케일링"
## 1 스케일링 1.0000000
## 2 받으로 0.4776843
## 3 치석 0.4223772
## 4 레지 0.3956734
## 5 군산 0.3839571
## 6 충치 0.3830556
## 7 치과 0.3690574
## 8 치료 0.3624082
## 9 시리 0.3588553
## 10 잇몸 0.3549760
“스케일링”의 경우는 유사도가 좀 낮습니다만, “레진(레지)”과 “충치”가 눈에 띄네요. “시리(시리다)”가 가장 높을 거라고 생각했는데 의외입니다. 레진이 문제가 됐거나, 스케일링 받으러 갔다 충치치료까지 반자의적으로 받게 된 것이 문제 제기 사유가 아닐까 생각해봅니다.
여러 단어를 통한 유사성 검색
여러 단어를 묶어서 유사 단어 검색도 할 수 있습니다. 치과 관련하여 생각나는 단어를 모아서 검색해볼까요?
w2v_model %>%
closest_to(w2v_model[[c('치과', '치아', '아말감', '레지', '신경', '크라운', '잇몸', '교정', '발치', '스케일링')]], 50)
## word similarity to w2v_model[[c("치과", "치아", ...]]
## 1 치아 0.8031644
## 2 레지 0.7221436
## 3 크라운 0.7221436
## 4 충치 0.7088742
## 5 씌우 0.6902271
## 6 아말감 0.6596279
## 7 어금니 0.6480453
## 8 치과 0.6384652
## 9 보철 0.6337940
## 10 덧니 0.6314725
## 11 잇몸 0.6189117
## 12 유치 0.6183702
## 13 스케일링 0.6154392
## 14 발치 0.6129797
## 15 도자기 0.6082379
## 16 가지런 0.5974331
## 17 개도 0.5973616
## 18 브릿지로 0.5896292
## 19 앞니 0.5881013
## 20 코아 0.5871983
## ...
(시각적 편의를 위해 정리한 자료임을 알려드립니다.)
치과 관련한 단어들이 모이는 것을 볼 수 있습니다. “어금니”, “보철”, “덧니”, “유치, “도자기” 등을 보니, 의미군이 어느 정도 형성된 것으로 보입니다.
정렬
이번엔 특정 단어군을 모아 시각화해보려고 합니다. 보존 관련 단어인 “아말감”, “레지(레진)”, “신경”, “코아”와 유사한 단어를 모아 펼쳐볼까요.
restoration <- closest_to(w2v_model, w2v_model[[c('아말감', '레지', '신경', '코아')]], 100)
rest <- w2v_model[[restoration$word, average=F]]
vectors <- stats::predict(stats::prcomp(rest))[ ,1:2]
graphics::plot(vectors, type='n')
graphics::text(vectors, labels=rownames(vectors), cex=0.7, family="Apple SD Gothic Neo")
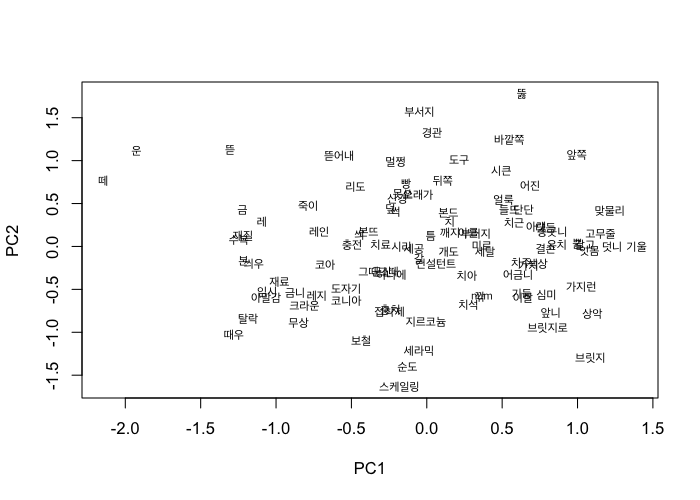
원래는 모델에서 추출해 바로 plot을 적용하면 되는데, 한글이 출력되지 않는다는 문제가 있습니다. 따라서, 코드에서 plot(mode="pca") 부분을 추출해서 직접 그려보았습니다. PCA 도표니 축을 그리면 좋은데, 단어 벡터는 축이 너무 많기 때문에(화살표 때문에 정신 없어서 아무것도 안보입니다) 단어들의 수평, 수직 관계를 살펴보시면 도움이 됩니다. 예컨대, “떼운”, “뜯어내”, “부서지”, “뚫” 같은 단어가 같은 수평 축에, “때우”, “탈락, “수복”, “재질” “금” 등이 같은 수직 축에 위치해 있는 걸 보면 이들이 비슷한 의미 계열에 있음을 생각해 볼 수 있습니다. 또, 비슷한 의미를 가지는 단어가 군집을 형성하게 됩니다. 예를 들면 좌측 하단에 “도자기”, “코니아”, “레지”, “크라운”, “금니”, “아말감”, “재료”의 군집이 보이네요.
군집 분석
그래서, 군집 분석입니다. 벡터를 200개로 설정했으니 축을 200개로 잡고, K-means algorithm으로 군집을 만들어보았습니다. 비슷한 중심점으로 모인 단어들을 보면 꽤 흥미롭습니다.
centers <- 200
clustering <- kmeans(w2v_model, centers=centers, iter.max = 40)
sapply(c(2:3, 11, 19, 28, 35:37, 46:47), function(n) {
names(clustering$cluster[clustering$cluster==n][1:10])
})
## [,1] [,2] [,3] [,4] [,5] [,6] [,7]
## [1,] "가격" "선택" "측" "대학" "접종" "의료" "기록"
## [2,] "비싸" "행위" "요구" "정형외과" "소아과" "사고" "인지"
## [3,] "배" "이용" "요청" "전문" "예방" "기관" "의무"
## [4,] "동일" "목적" "거부" "일산" "국가" "의료진" "여부"
## [5,] "차이" "과다" "규정" "신경외과" "간염" "처치" "차트"
## [6,] "행사" "유도" "전액" "세브란스" "항체" "의료행위" "작성"
## [7,] "비슷" "혹은" "불가" "아산" "사이트" "스스로" "허위"
## [8,] "저렴" "과잉" "주장" "현대" "참조" "휴" "거짓"
## [9,] "비교" "대상" "거절" "순천" "아동" "어려움" "수정"
## [10,] "종류" "불필요" "정당" "한림대" "a형" "문제점" "고의"
## [,8] [,9] [,10]
## [1,] "감염" "임플란트" "맞추"
## [2,] "균" "보철" "교합"
## [3,] "의학" "깨지" "중심"
## [4,] "출입" "흔들리" "위아래"
## [5,] "안전" "틀니" "틀어지"
## [6,] "외부" "as" "미르"
## [7,] "일반인" "나사" "덧니"
## [8,] "아무도" "제작" "가지런"
## [9,] "바이러스" "보증" "기울"
## [10,] "입구" "라미" "일치"
첫번째 군집은 가격, 행사 관련, 세번째 군집은 아마 환불 관련인 것 같네요. 치과 내용으로는 아홉번째의 보철, 열번째의 교정 군집 단어들을 보실 수 있습니다. 이렇게 모아놓으니, topic modeling과 비슷하다는 생각도 드네요.
단어 네 개에 가장 가까운 단어 10개를 모아 dendrogram을 그려보았습니다.
# 10 words closest to each of 4 different kinds of words
domain <- c("임플란트", "교정", "레지", "크라운")
term_set <- lapply(domain, function(area) {
nearest_words = w2v_model %>% closest_to(w2v_model[[area]], 10)
nearest_words$word }) %>%
unlist
subset <- w2v_model[[term_set, average=F]]
subset %>%
cosineDist(subset) %>%
as.dist %>%
hclust %>%
ggdendrogram(rotate=TRUE, theme_dendro=FALSE) +
theme(text=element_text(family="Apple SD Gothic Neo"))
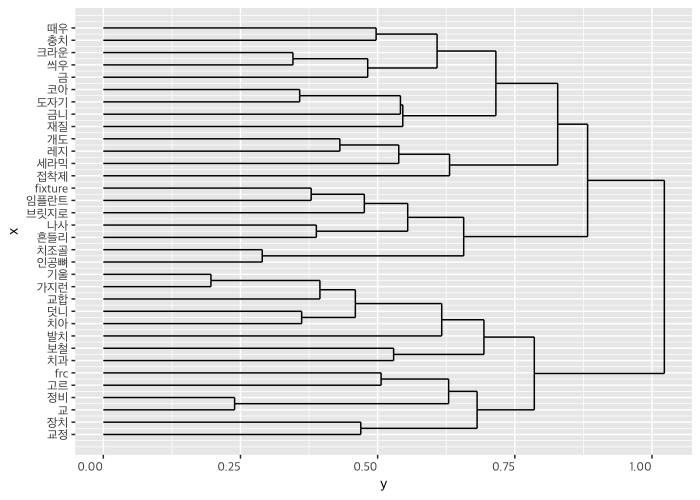
보존/임플란트/교정의 단어 군집을 잘 확인할 수 있습니다. 문제를 상담한 내용이었다는 것에 기반하여 생각해보면, 여러 가지를 생각해볼 수 있는 자료가 됩니다. 예컨대 덧니 때문에 발치 교정을 한 것과 관련한 문제 제기와, 교정 장치와 그 정비 관련 문제 제기는 좀 거리가 있다는 것을 알 수 있습니다.
중심 단어를 통한 시각화
중심 단어를 뽑아, 그 단어를 축으로 해 인접 단어를 시각화할 수 있습니다. 먼저 한 번 볼께요.
anesthesia <- w2v_model[[c("치과", "마취"), average=F]]
# 모형에 상위 2000번째 단어까지만 사용합니다.
dental_anesthesia <- w2v_model[1:2000, ] %>%
cosineSimilarity(anesthesia)
# 관련 상위 20등까지의 단어만 추출합니다.
dental_anesthesia <- dental_anesthesia[
rank(-dental_anesthesia[ ,1]) < 20 | rank(-dental_anesthesia[ ,2]) < 20,
]
plot(dental_anesthesia, type='n', family="Apple SD Gothic Neo")
text(dental_anesthesia, labels=rownames(dental_anesthesia), family="Apple SD Gothic Neo", cex=0.7)
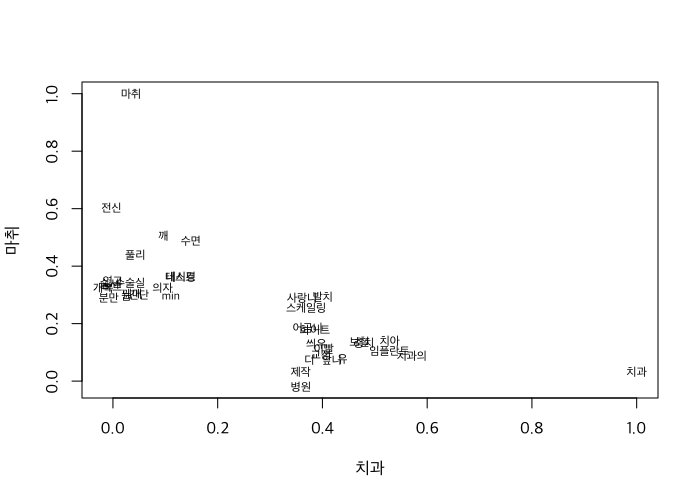
치과와 마취의 의미가 명확히 구분되는 것을 볼 수 있습니다. 단어가 몰려 있어 잘 안보이는게 아쉽지만, 구분선을 명확히 그을 수 있네요. 치과 관련해서 마취가 문제가 된 상담은 없다고 생각해 볼 수 있겠습니다.
유사도 통한 시각화
다음은 유사도를 기반으로 해 중요 단어를 추출하여, “치과” 의미 공간을 만들어 보겠습니다.
# Shrink down to 3 dimensions
areas <- w2v_model[[c("임플란트", "교정", "크라운"), average=F]]
common_similarities_areas <- w2v_model[1:2000, ] %>%
cosineSimilarity(areas)
common_similarities_areas[30:40, ]
## 교정 임플란트 크라운
## 진료 0.17039530 0.14155053 0.043280376
## 환자 0.06639226 0.06228307 -0.001342093
## 제가 0.20091055 0.08513487 0.247107211
## 다시 0.14570941 0.24306914 0.176817190
## 환불 0.23492688 0.15721559 0.108284078
## 다른 0.15971624 0.17560611 0.153367926
## tim 0.16883519 0.13333751 0.164624962
## 같 0.11627311 0.06244281 0.180589416
## 때 0.17900855 0.13270822 0.167448256
## 치과 0.39742118 0.52827308 0.329016688
## 전 0.15288083 0.11455313 0.138812243
# filter down to 50 words
high_similarities_to_areas <- common_similarities_areas[rank(-apply(common_similarities_areas, 1, max)) < 75, ]
high_similarities_to_areas %>%
prcomp %>%
biplot(main="Fifty words in a\nprojection of dental space", expand=5, family="Apple SD Gothic Neo", cex=0.5)
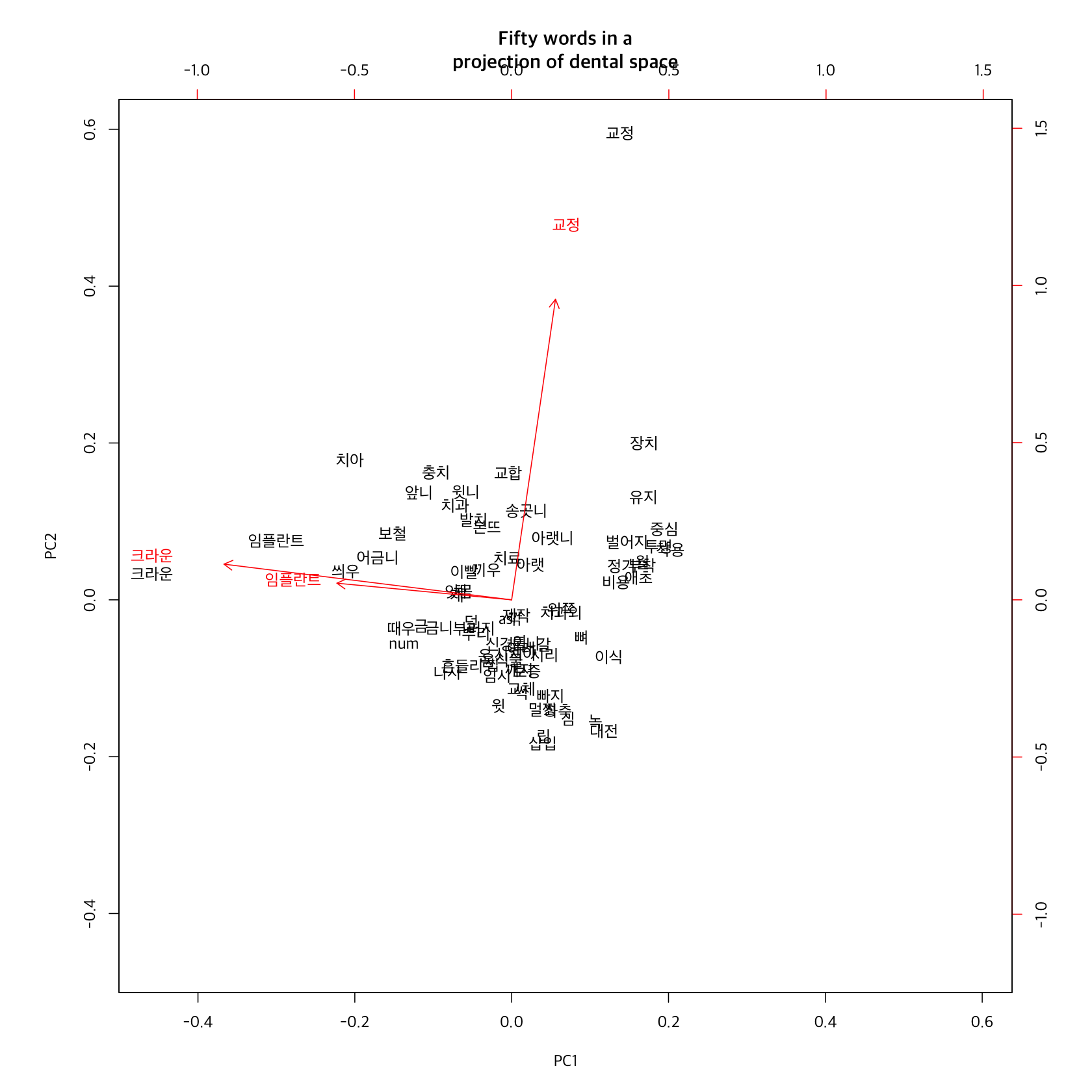
먼저 교정은 환불과 근접성이 가장 높고, 치과와 근접성이 가장 높은 것은 임플란트라는 점이 흥미롭습니다. “교정”과 “임플란트”, “크라운”은 상당히 다른 의미 축을 가지고 있고, 교정은 유지장치, 벌어짐, 비용 관련해서 문제가 되고, 별도의 어휘군으로 문제가 정의된다면 보철은 독립적인 문제항을 별도로 구성하지는 않는 것 같습니다.
마지막, t-SNE
t-SNE는 고차원 벡터를 시각화할 때 유용하게 사용할 수 있는 방법입니다. PCA보다도 훨씬 군집을 잘 보여주지요.

이 그림에서 볼 수 있는 것처럼, 군집 구조를 더 잘 나눠서 표현해줍니다. R에서도 그려볼 수 있고요.
temp <- as.matrix(w2v_model)
short <- temp[1:100, ]
m <- tsne(short, perplexity=50)
tsne.out <- data.frame(x=m[,1], y=m[,2])
ggplot(tsne.out) +
geom_text(aes(x=x, y=y, label=rownames(short), size=((100:1)/400)^(1/2)), family="Apple SD Gothic Neo") +
theme(legend.position="none")
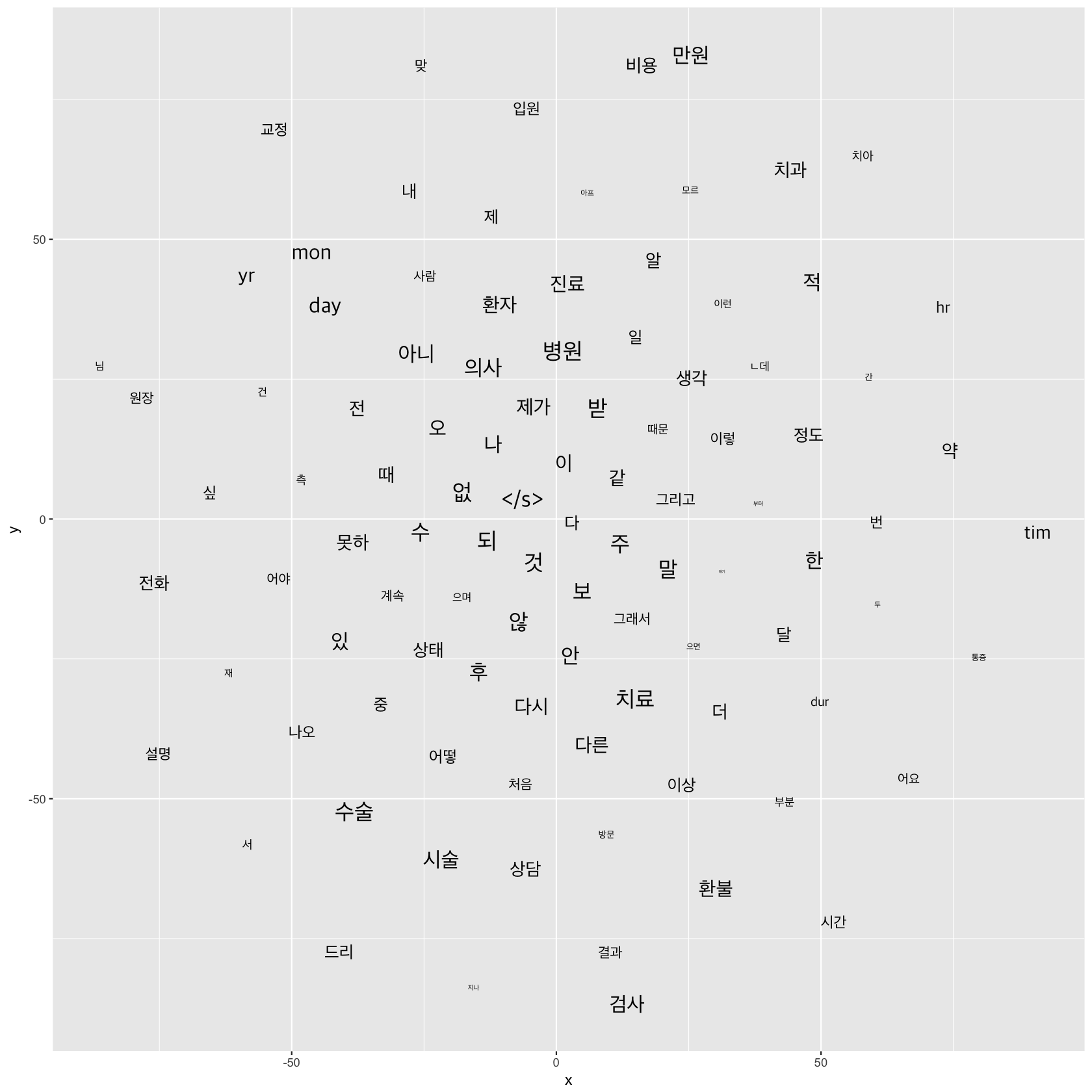
상위 100개 단어만 시각화해 보았습니다. 의료서비스 관련 전체 상담 내용이기 때문에, 여기에는 치과 내용만 표시되지는 않습니다. tim, mon, yr, day 등은 숫자를 대체한 태그이고, “ㄴ데”, “/s” 등은 제외해야 겠습니다. 다음 번에 치과, 치아와 반대쪽에 있는 수술, 시술, 설명, 상태 등을 중심으로 해서 확인해보면 좋겠네요.
마치며
일단 이번에는 Word Vector의 소개와, 어떤 결과를 만들 수 있는지만 확인해 보았습니다. 개인적으로 의과와는 구분되는 치과의 특징을 확인해보고 싶었는데 이 내용을 적으려면 너무 길어질 것 같네요. 다음번에 좀 더 세부적인 내용을 소개하도록 할게요!
Comments