한국 가요 50년사, 가사 분석
멜론 시대별 차트는 미국 빌보드처럼 공식 가요 순위 기록이 없는 한국 가요를 여러 출처를 통해 정리한 좋은 자료입니다. 물론 음원 공급을 하는 특정 회사의 저작물이라는 한계가 있을 수 있으나, 2010년 이후부터는 멜론 차트가 한국 가요 순위를 말하는 데에 있어서 중요한 지표가 된 것도 사실이니까요. 시대별 차트는 1964 ~ 2016년도의 가요 차트를 보여줍니다. 64 ~ 83년도는 순위 없이 해당 연도의 인기곡을, 84 ~ 04년도는 무가지 뮤직박스 차트를, 05년도 이후는 멜론 차트를 제공하고 있습니다. 이번 포스트는 전체 차트와 각 곡의 가사를 scraping한 자료를 토대로 명멸해간 스타들, 그리고 가사를 중심으로 한 분석 기법들의 소개를 이어가려 합니다. 이번에는 순위 자료를 바탕으로 한 graph와 가사의 word cloud, tf-idf 기반 분석을 소개하고, 다음 포스트에서 word vector, stm (structural topic modeling)을 다뤄보고자 합니다.
자료와 scraping 방법은 github의 자료 및 R script를 참고해주세요. 더불어 이 포스트는
- [50 Years of Pop Music Lyrics] (https://github.com/walkerkq/musiclyrics)
- [Case study: analyzing usenet text] (http://tidytextmining.com/usenet.html)
를 기반으로 하여 작성하였습니다 (원 포스트의 코드를 tidyverse로 refactoring하였습니다). 기본 graph 또한 본 포스트에서는 분석만을 제공합니다. 궁금하신 점은 문의해주세요.
한국 가요를 빛낸 스타들
먼저 총 3969곡이 수집되었습니다. 이중, 약 4%에 해당하는 165곡의 가사는 멜론에 등록되어 있지 않았습니다.
<표: 차트 출현 빈도>
| Freq | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 22 | 23 | 24 | 26 | 27 | 32 | 41 |
| n | 456 | 199 | 114 | 78 | 41 | 46 | 40 | 22 | 18 | 11 | 13 | 8 | 9 | 7 | 8 | 5 | 7 | 2 | 2 | 2 | 2 | 2 | 1 | 2 | 1 | 1 | 1 |
먼저 차트에 이름을 올린 가수들을 살펴볼게요. 한 분 한 분을 언급하는 건 다른 글에서 다루도록 하고, 여기에선 통계적인 분석에 집중하려 합니다. 먼저 ‘원 히트 원더(one-hit wonder)’, 차트에 한 번만 이름을 올린 가수는 전체의 41.5% (456명)입니다. 한 곡을 두 명 이상의 가수가 부른 경우는 제외했어요. 빌보드의 58%에 비하면 현저히 낮은 수치이지만, 83년까지의 차트가 20~30곡으로만 만들어져 있기 때문에 나타나는 편향인 것으로 보여요.

다음은 불멸의 영예를 안은 가수들을 살펴볼게요. 차트에 이름을 올린 곡의 수대로 나열해 보았습니다. 역시 가왕 조용필이 41곡으로 최다 곡수를 자랑하고 있어요. 빅뱅이 2등인 건 의외라고 해야 할까요. 각자의 활동과 유닛 활동까지 생각하면 그들의 영향력은 어마 무시합니다. 이어서 이선희, 이승철, 이문세, 이미자의 이름이 보이네요. 각기 시대를 대표한 가수들이죠. 또, 다비치와 SG워너비가 음원 강자라더니, 차트를 정리하니 확 실감하게 됩니다. 10위권 안일 거라고는 생각도 못했는데요.

이어서 곡수로 그려본 히스토그램입니다. 중간에 5곡보다 6곡을 올린 가수의 수가 많다는 점이 흥미로워요. 예상대로 long-tail 분포를 보여주고 있네요.

가수 두 명(또는 팀) 이상이 함께 참여하여 부른 노래입니다. 흔히 피처링(featuring)이라고 하죠. 2005년까지는 거의 없다가, 갑자기 증가하는 양상을 보이고 있네요.
커리어 도표
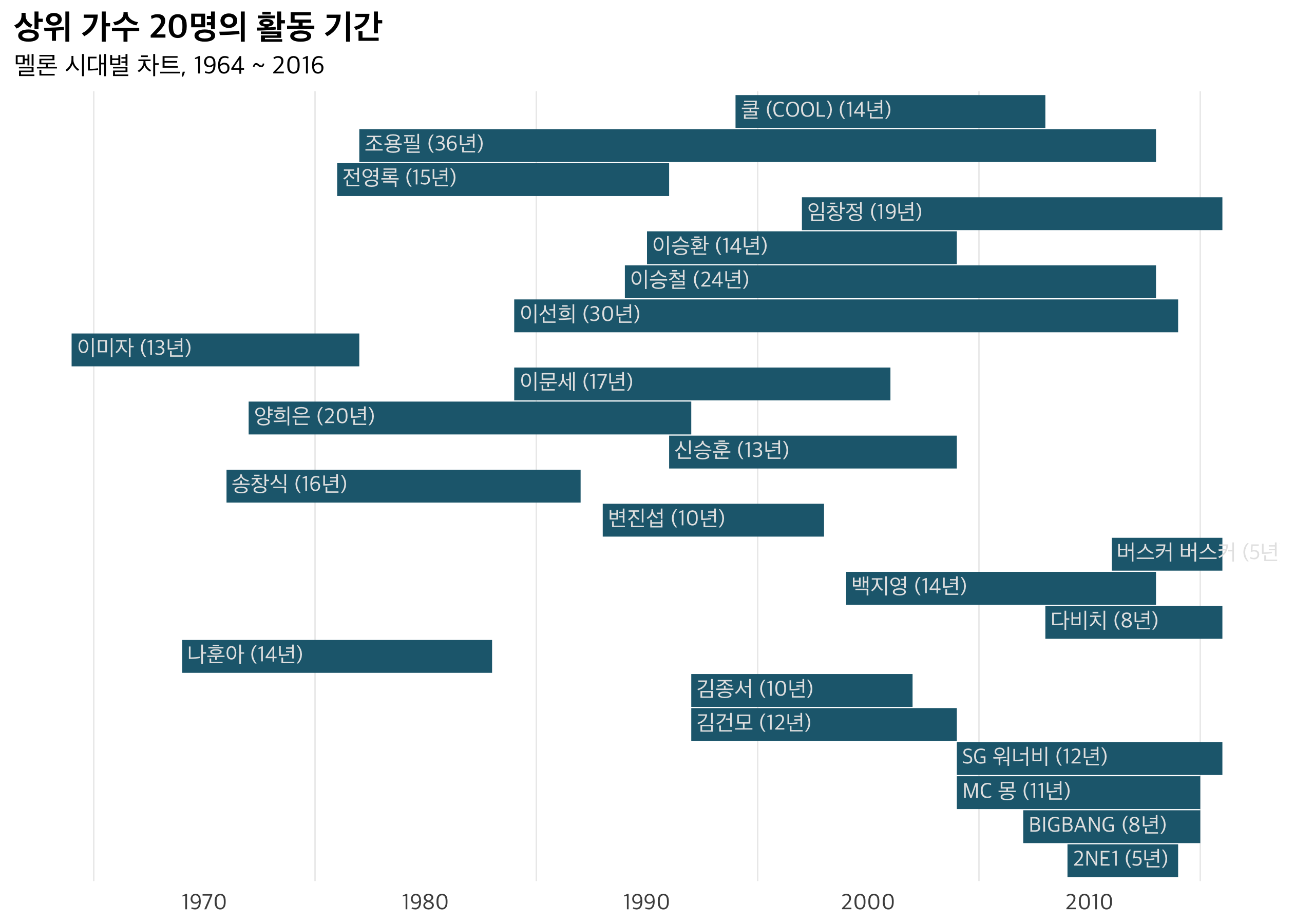
다음은 차트에 처음 이름을 올린 순간부터 마지막 등장한 시점까지를 통해 구한 가수의 활동 기간이에요. 60 ~ 70년대의 이미자, 나훈아, 송창식, 양희은부터 시대를 빛낸 가수들의 이름이 보이네요. 역시 빅뱅, 8년 동안 수많은 곡을 올렸다는 점에서 그들의 노력을, 시대를 뛰어넘어 36년 동안 차트에 이름을 올린 가왕 조용필의 위업에 경의를 바칩니다. 빌보드의 경우 가장 활동이 길었던 마이클 잭슨이 30년인걸요.
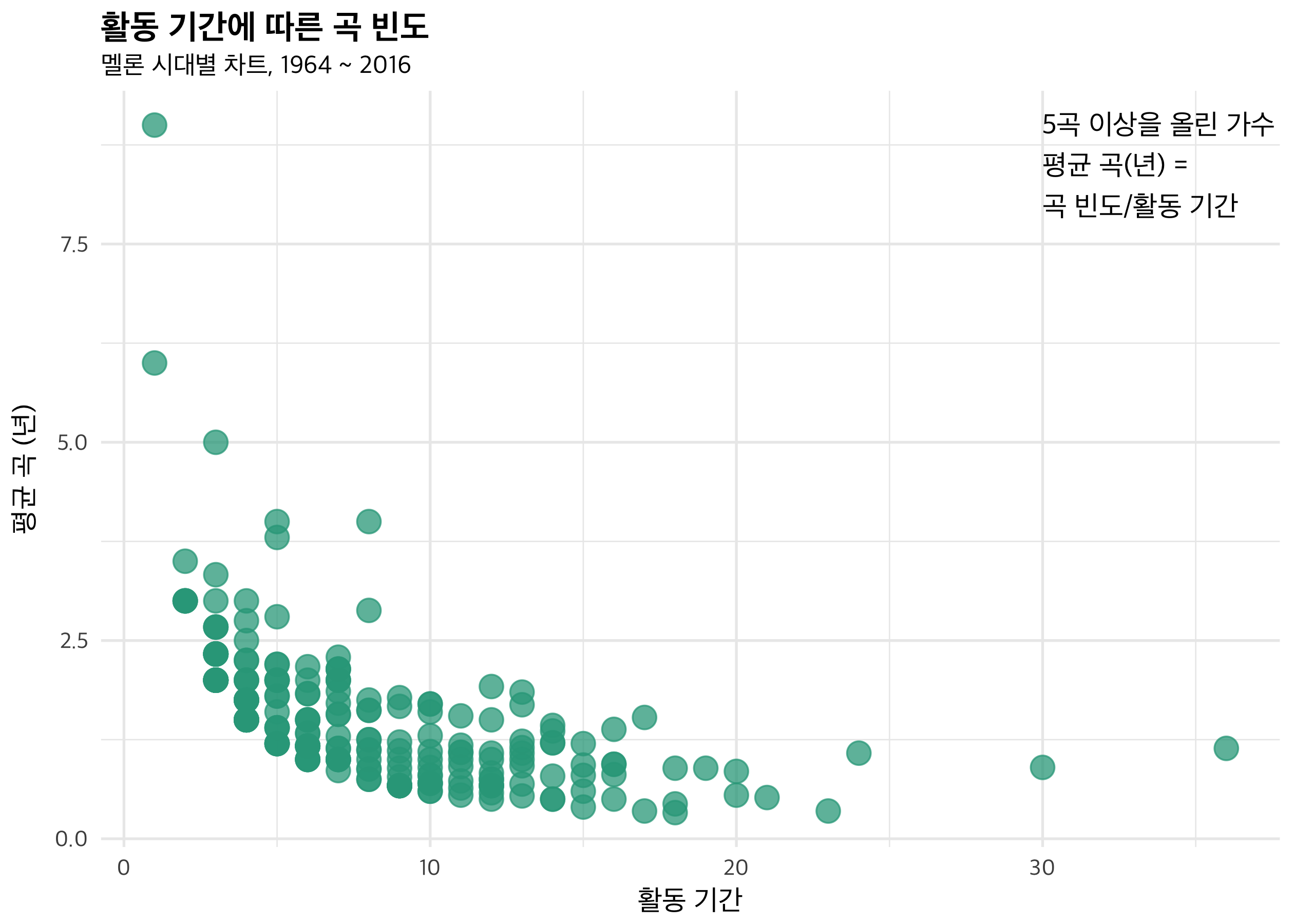
활동 기간에 따른 년 당 평균 곡 수입니다. 아무래도 활동기간이 짧을수록 해마다 발표하고 차트에 이름을 올리는 빈도가 더 높네요. 왼쪽 끝은 1984 ~ 5년에 활동한 가수 임병수입니다. 1년 동안 9곡이라니 굉장하네요. 그의 곡 ‘아이스크림 사랑’은 ‘응답하라 1988’에도 나왔었군요.
가사 분석
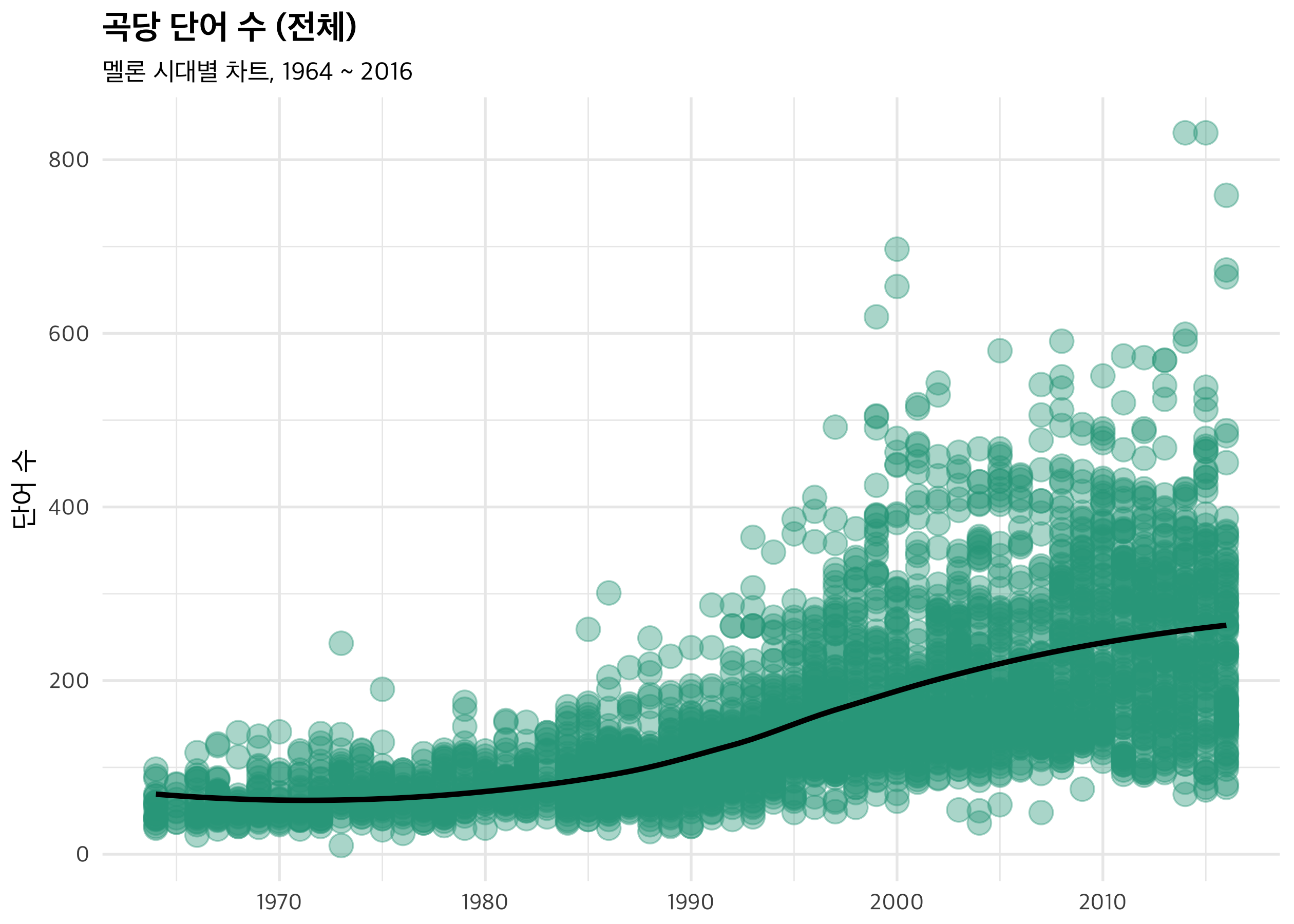
이제 가사 분석입니다. 먼저 숫자부터 보겠습니다. 가사는 점점 길어지고 있어요. 60 ~ 70년대 ~ 100 단어이던 가사는 이제 800단어가 넘는 곡까지 나타나는 상황으로 바뀌었네요. 물론 천차만별이겠지만, 평균적으로 200단어 안팎으로 단어 수가 증가한 것은 확실히 나타납니다.
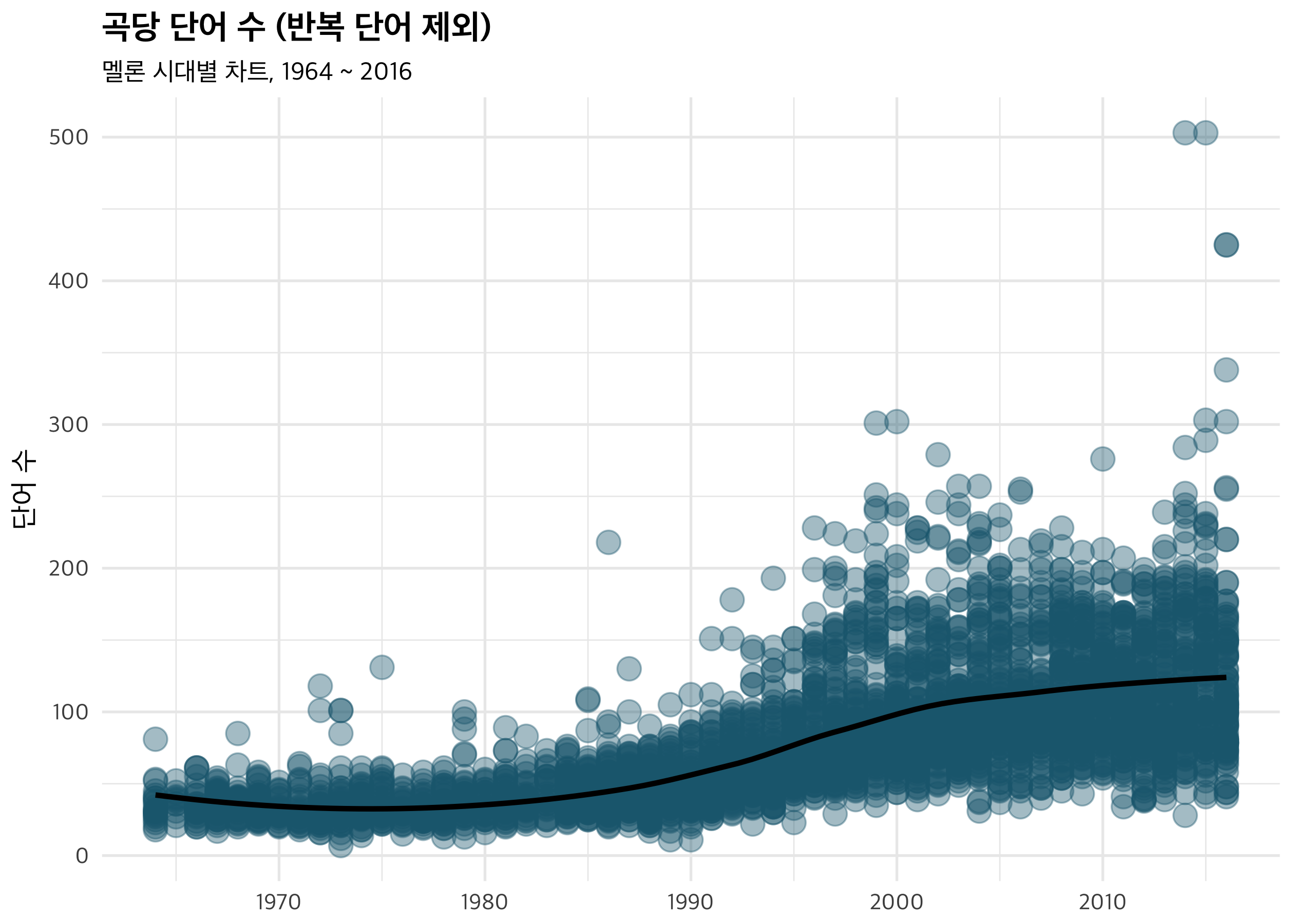
그럼 반복되는 단어를 제외해보면 어떨까요? 일단 최댓값이 500단어로 줄었어요. 패턴 지체는 비슷하게 나타나네요. 반복되는 부분은 아마 후렴이었던 것 같고요. 전체적으로 단어 수는 줄어들고 더 균일해지는 모습을 보이는 것을 알 수 있습니다.
Tf-idf 분석
이번 포스트에서 코드를 설명드릴 부분은 여기부터입니다. 가사를 tidytext와 RmecabKo 패키지를 통해 분석해볼 거예요. 이번에 제가 RmecabKo를 업데이트하면서 tokenizer를 추가했거든요. 업데이트 관련 설명은 포스트를 참조해 주세요.
먼저 텍스트 분석과 시각화에서 wordcloud를 빼놓을 수 없죠. 간략하게 보고 갈까요?
songListLyrics <- songListLyrics %>%
na.omit() %>%
mutate(decade = floor(year / 10) * 10)
lyricsWords <- songListLyrics %>%
unnest_tokens(word, lyric, token = token_words)
lyricsWords %>% anti_join(stopwords_ko) %>%
anti_join(stop_words) %>%
count(word, sort = TRUE) %>%
head(20) %>%
kable()
| word | n |
|---|---|
| 사랑 | 10847 |
| 없 | 6918 |
| 말 | 6392 |
| 보 | 3323 |
| 마음 | 2865 |
| 사람 | 2739 |
| 싶 | 2531 |
| 다시 | 2527 |
| 잊 | 2408 |
| 알 | 2364 |
| 속 | 2348 |
| 눈물 | 2227 |
| 같 | 2153 |
| 봐 | 2082 |
| 가슴 | 2050 |
| 너무 | 1936 |
| 밤 | 1765 |
| 생각 | 1758 |
| 눈 | 1720 |
| 모습 | 1653 |
lyricsWords %>% anti_join(stopwords_ko) %>%
anti_join(stop_words) %>%
count(word) %>%
with(wordcloud(word, n, max.words = 100, family = "Apple SD Gothic Neo", colors = wes_palette("Cavalcanti")))

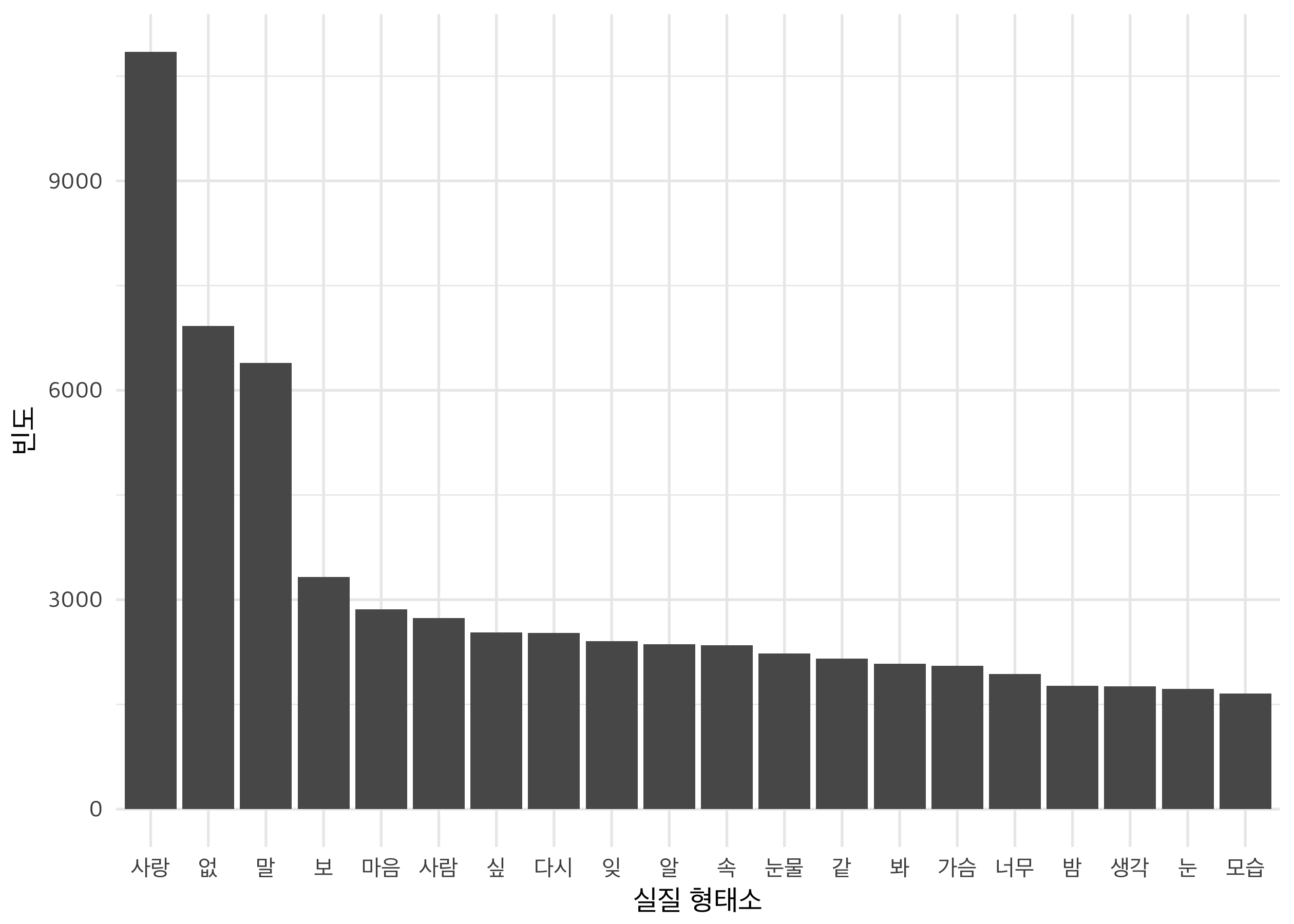
실질형태소 빈도 상위 20개와 wordcloud입니다. 당연히 “사랑”이 제일 많네요. “없(다)”, “말”이 뒤를 이어요. ‘없다’는 부정어에 공통적으로 등장하는 형태소니, ‘말’이 흥미롭네요. 전해야 했던 무언가, 말해야 했던 무언가가 중요한 의미를 차지하고 있는 것 같아요.
RmecabKo::token_words는 실질 형태소만 추출하여 토큰 형태로 제공합니다. tidytext::unnest_tokens의 token parameter에 입력해서 Mecab-Ko를 통한 형태소 분석 후 이를 tidy 형태의 자료로 만든 것을 보실 수 있어요.
lyricsWords %>%
count(word, sort = TRUE)
wordsByDecade <- lyricsWords %>%
count(decade, word, sort = TRUE) %>%
ungroup()
wordsByDecade
## # A tibble: 14,749 x 2
## word n
## <chr> <int>
## 1 나 14490
## 2 내 11833
## 3 너 11015
## 4 사랑 10847
## 5 있 7742
## 6 이 7007
## 7 없 6918
## 8 말 6392
## 9 그대 5732
## 10 수 5376
## # ... with 14,739 more rows
## # A tibble: 31,249 x 3
## decade word n
## <dbl> <chr> <int>
## 1 2000 나 4396
## 2 1990 나 4317
## 3 2000 내 4032
## 4 2000 사랑 3791
## 5 2000 너 3562
## 6 1990 너 3403
## 7 2010 나 3353
## 8 2010 내 3288
## 9 2010 너 3253
## 10 1990 있 2937
## # ... with 31,239 more rows
다음은 시대별(10년마다) 가사 변화를 분석하기 위해서 자료를 정리하는 과정이에요. 먼저 decade를 만들고 mutate(decade = floor(year / 10) * 10) %>% count(decade, word)를 통해 10년마다 가사의 형태소 빈도를 구한 모습입니다.
다음은 tf-idf 값을 구해볼 거예요. tf-idf (term frequency - inverse document frequency)는 단어의 빈도와 해당 단어가 등장한 문단 또는 텍스트의 빈도를 결합해서, 단순한 단어 빈도가 단어의 일반 빈도를 따라서 크게 의미 없는 단어(위의 ‘나’, ‘너’, ‘있’처럼요) 순서대로 나열되는 것을 피해 해당 텍스트에서의 중요도를 구할 수 있는 방법이에요. tidytext::bind_tf_idf로 간단하게 구할 수 있습니다. 코드를 볼까요?
tfIdf <- wordsByDecade %>%
bind_tf_idf(word, decade, n) %>%
arrange(desc(tf_idf))
tfIdf
## # A tibble: 31,249 x 6
## decade word n tf idf tf_idf
## <dbl> <chr> <int> <dbl> <dbl> <dbl>
## 1 1960 마리아 35 0.0035457400 0.6931472 0.002457720
## 2 1970 목화밭 32 0.0011953679 1.7917595 0.002141812
## 3 1960 마도로스 10 0.0010130686 1.7917595 0.001815175
## 4 1970 얄리 36 0.0013447889 1.0986123 0.001477402
## 5 1960 김일병 8 0.0008104549 1.7917595 0.001452140
## 6 1960 부기우기 8 0.0008104549 1.7917595 0.001452140
## 7 2000 널 1275 0.0078966927 0.1823216 0.001439737
## 8 2010 어머 108 0.0007860319 1.7917595 0.001408380
## 9 2010 널 982 0.0071470680 0.1823216 0.001303065
## 10 1960 천리 11 0.0011143754 1.0986123 0.001224267
## # ... with 31,239 more rows
보시는 것처럼 단어 자체의 빈도(tf)에 단어가 등장한 텍스트의 빈도의 역수(idf)를 결합해서 구한 tf-idf는 해당 텍스트 뭉치에서 중요한 단어를 찾아낼 수 있는 좋은 값입니다. 60년대의 “마리아”, “김일병”, “마도로스”나 70년대의 “목화밭”, “얄리”가 시대를 잘 보여주고 있는 것처럼요.
tfIdf %>%
group_by(decade) %>%
top_n(12, tf_idf) %>%
ungroup() %>%
mutate(word = reorder(word, tf_idf)) %>%
ggplot(aes(word, tf_idf, fill = decade)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ decade, scales = "free") +
ylab("tf-idf") +
coord_flip()
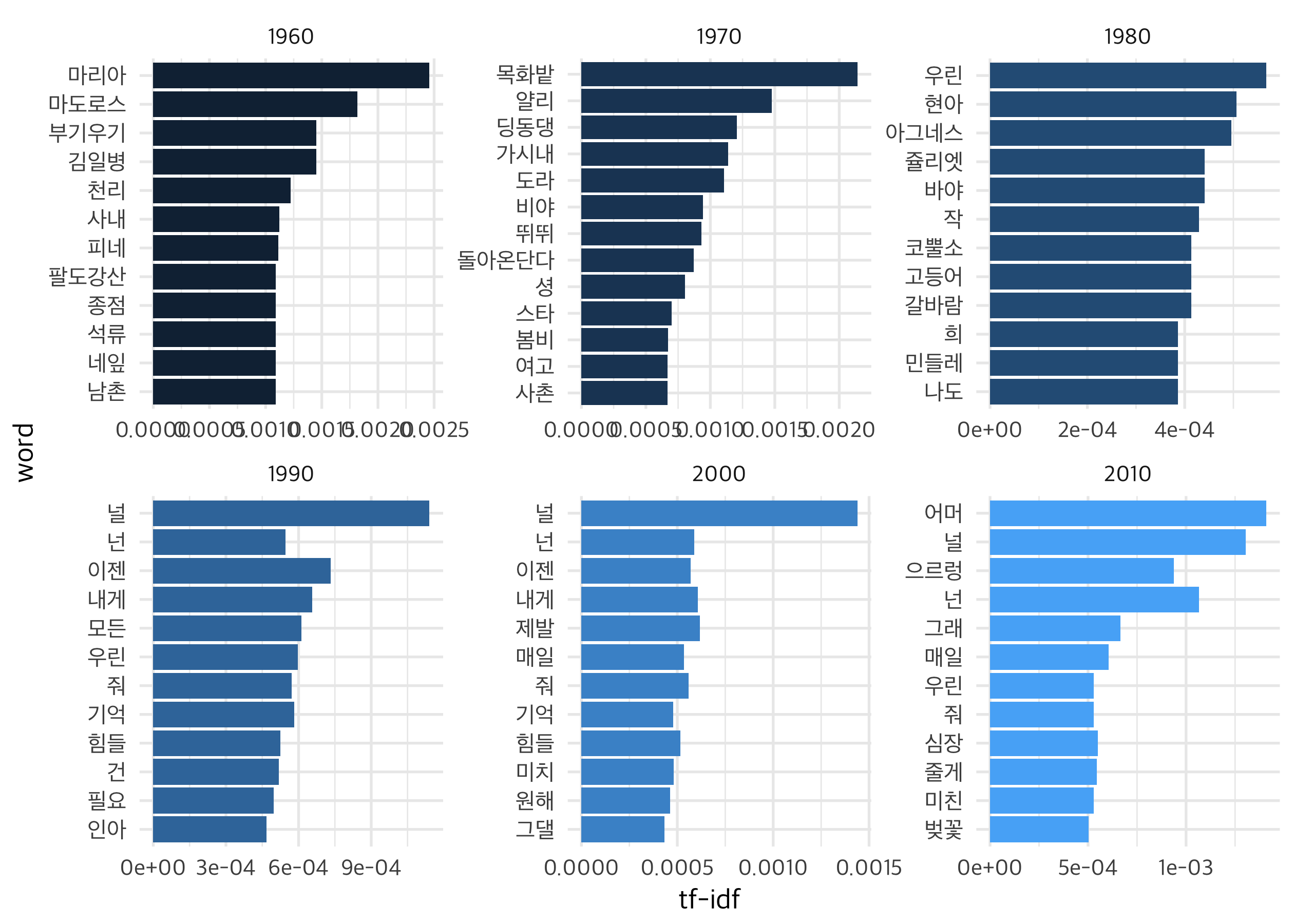
tf-idf 값을 통해 시대별로 중요한 단어를 뽑아보았어요. 60년대는 “마리아”를 놓고 “마도로스”, “김일병”이 다투던 시기였을까요. 70년대의 “얄리”, “가시내”는 80년대의 “현아”와 “아그네스”, “쥴리엣”으로 이름을 바꿉니다. 90년대 이후에는 “너”가 직접 등장하는 것을 볼 수 있어요. 90년대 이후는 다 비슷하냐면 그렇지도 않죠. 일단 2010년대의 “어머”와 “으르렁” (엑소도 엄청나군요)이 있고요. 전체적 정서를 보자면 90년대는 ‘힘든 기억’을 잊고 ‘이제 우리’를 이야기하고 있어요. 2000년대는 ‘힘든 기억’이 ‘미치’게 하고 있군요. ‘이제 제발’ 뭔가를 해야 한다는 것 같아요. 한편 2010년대는 ‘벚꽃’ 아래서 ‘심장’을 ‘주려’나요?
library(widyr)
decadeCors <- wordsByDecade %>%
pairwise_cor(decade, word, n, sort = TRUE)
decadeCors
## # A tibble: 30 x 3
## item1 item2 correlation
## <dbl> <dbl> <dbl>
## 1 2010 2000 0.9709446
## 2 2000 2010 0.9709446
## 3 1990 2000 0.9627939
## 4 2000 1990 0.9627939
## 5 2010 1990 0.9313528
## 6 1990 2010 0.9313528
## 7 1970 1980 0.9182174
## 8 1980 1970 0.9182174
## 9 1980 1990 0.8917859
## 10 1990 1980 0.8917859
## # ... with 20 more rows
마지막으로 단어 correlation을 통한 시대별 연관 네트워크를 그려볼게요. widyr::pairwise_cor를 통해 correlation을 쉽게 구할 수 있어요. widyr 패키지는 다음 번 word vector 구축에서도 중요하게 사용될 예정입니다.
library(ggraph)
library(igraph)
decadeCors %>%
filter(correlation > .4) %>%
graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(alpha = correlation, width = correlation)) +
geom_node_point(size = 6, color = "lightblue") +
geom_node_text(aes(label = name), repel = TRUE, color = "grey60") +
theme_void()

마지막으로 ggraph와 igraph 패키지를 사용해 간단한 연관 network를 그려보았어요. 1960년도와 2010년도는 연관성이 많이 낮네요. 앞뒤 시대는 서로 연관성을 가지고 가사가 점차 변화하고 있음을 알 수 있어요. 당연한 결과일까요?
마치며
이번 분석은 한국 가요 가사 분석 1편이었어요. 먼저 자료의 연도 값을 통해 여러 도표를 그려보았어요 (조용필 선생님 존경합니다). 이어서 가사를 tf-idf로 분석하고, 연관성 네트워크를 그렸습니다. 한국 가요의 변화 양상이 눈에 들어오셨을까요? 다음 word vector와 stm 분석도 기대해 주세요. 감사합니다!
Comments